kotlin中inline,noinline,crossinline区别?
- 默认函数中如果没加inline,那就是非内联函数,此时lambda会生成一个新的类,该类是继承自Lambda抽象类,并实现了Function接口,其中invoke方法就是Function接口的方法,invoke中的方法就是lambda代码块的代码。
- 内联函数(加inline关键字)的lambda如果没加noinline或crossinline,默认会把lambda的代码块给平铺到调用处,所以此时如果在lambda中加return的话,会直接不执行外层函数后续代码。如果是非内联函数的话,由于它是生成一个单独的类,不存在平铺代码,所以return是编译不过去的。
- noinline和inline是对立关系,它是将lambda不内联处理,如果你需要对该lambda作为对象来使用的时候,此时需要用到noinline,如果一个内联函数都是noinline的lambda表达式,那么此时as会提示你此处可以去掉inline关键字了,当做普通的高阶函数来处理就行。
- 默认内联函数是能添加return来作为局部返回,由于存在平铺代码的特性,所以它能阻止调用lambda的外层函数的执行,那如果lambda作为间接调用的时候,此时添加return语句会编译失败,因为间接调用(比如匿名内部类或回调)不能阻止外层函数的调用,是为了避免多线程或回调中意外终止外层函数,所以kotlin编译器此时需要你添加crossinline,举个例子就清楚了:
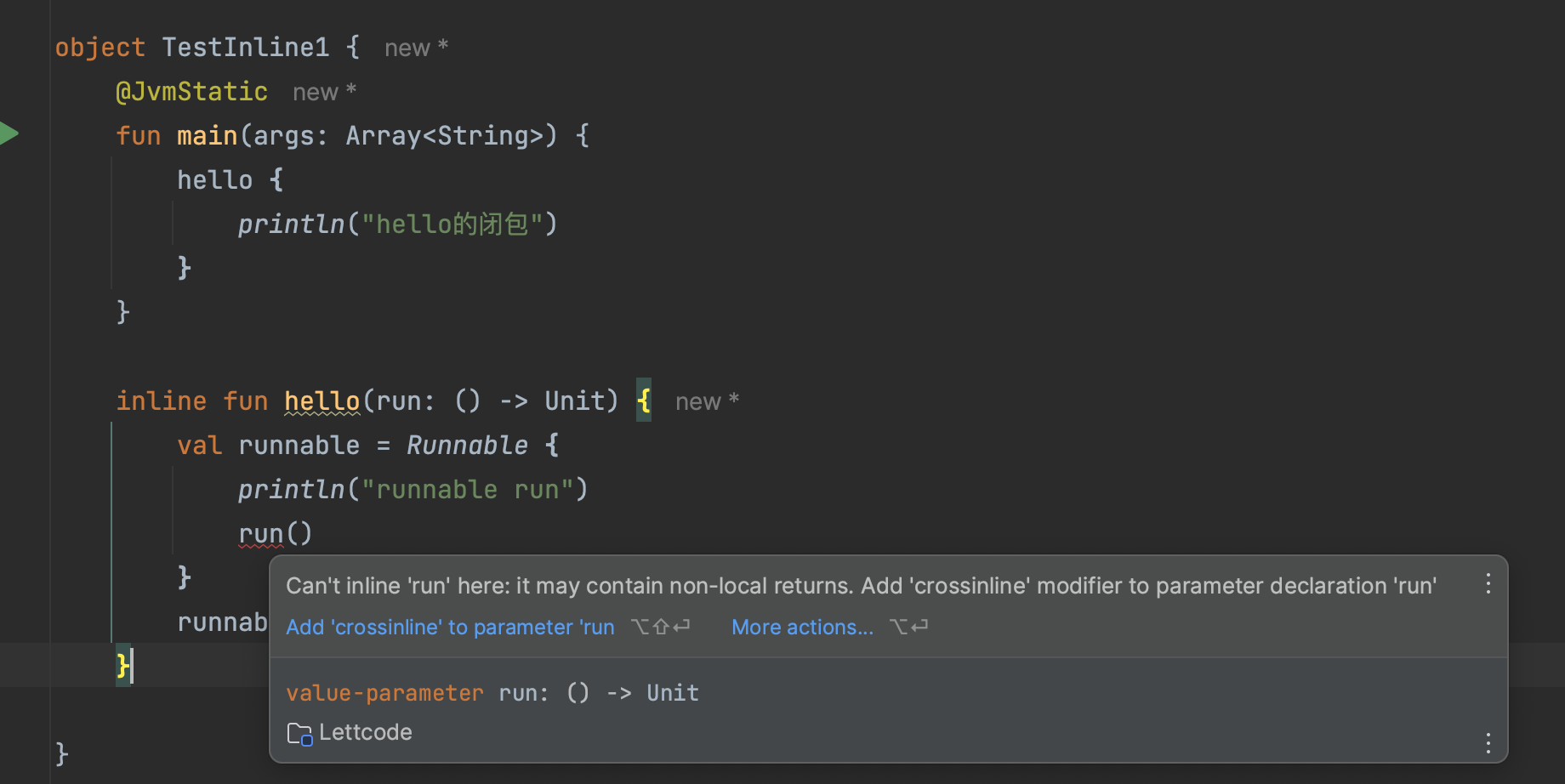 此处的run闭包,它的调用是在runnable接口中的,此时编译器提示
此处的run闭包,它的调用是在runnable接口中的,此时编译器提示it may contain non-local returns,意思是此时存在间接调用,在间接调用lambda的时候,不允许在lambda中添加return来阻止外层的外层函数的执行。所以此处通过添加crossinline来阻止lambda中添加return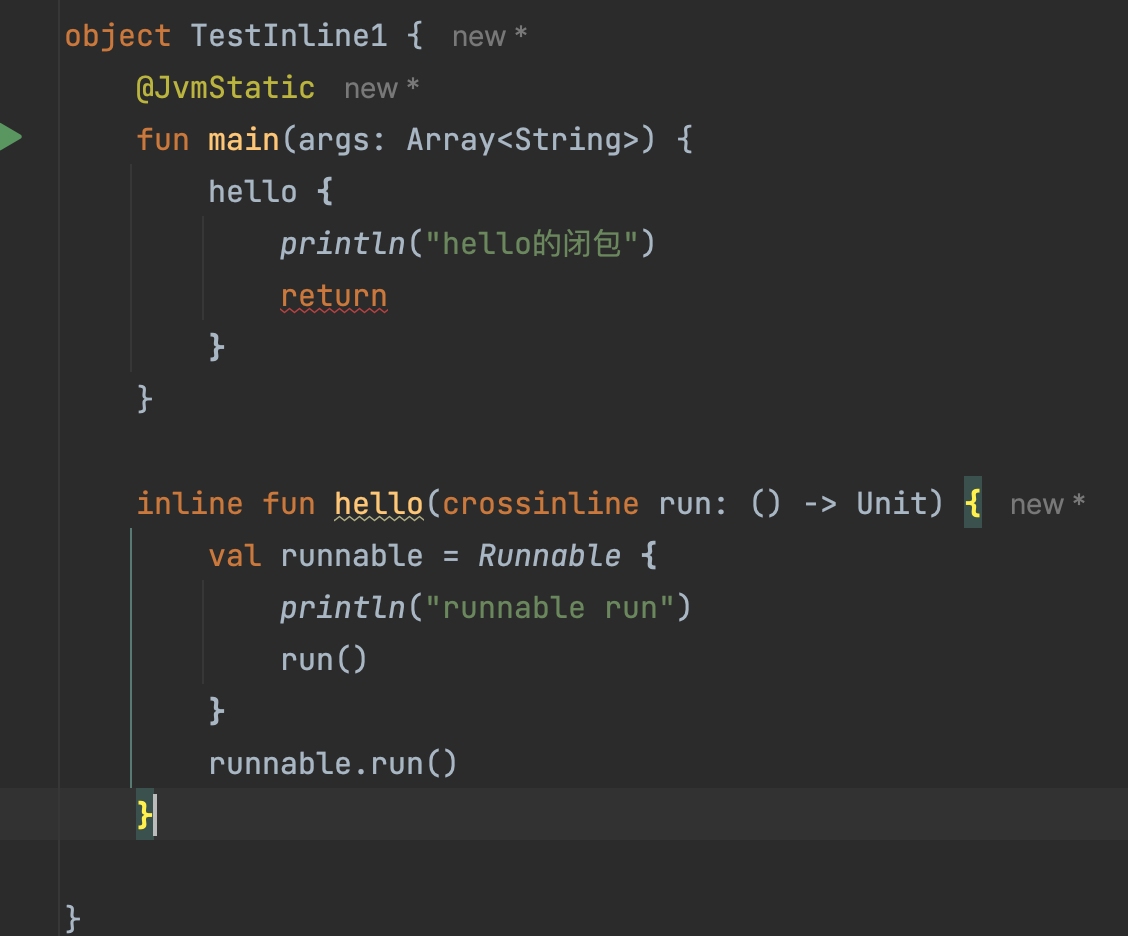 疑惑:crossinline添加后,内联效果还在吗?还是以上面的例子来说明:
假如上面的hello方法我就作为普通的方法,如下:
对应的字节码如下:
疑惑:crossinline添加后,内联效果还在吗?还是以上面的例子来说明:
假如上面的hello方法我就作为普通的方法,如下:
对应的字节码如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16object TestInline1 { @JvmStatic fun main(args: Array<String>) { hello { println("hello的闭包") } } fun hello(run: () -> Unit) { val runnable = Runnable { println("runnable run") run() } runnable.run() } }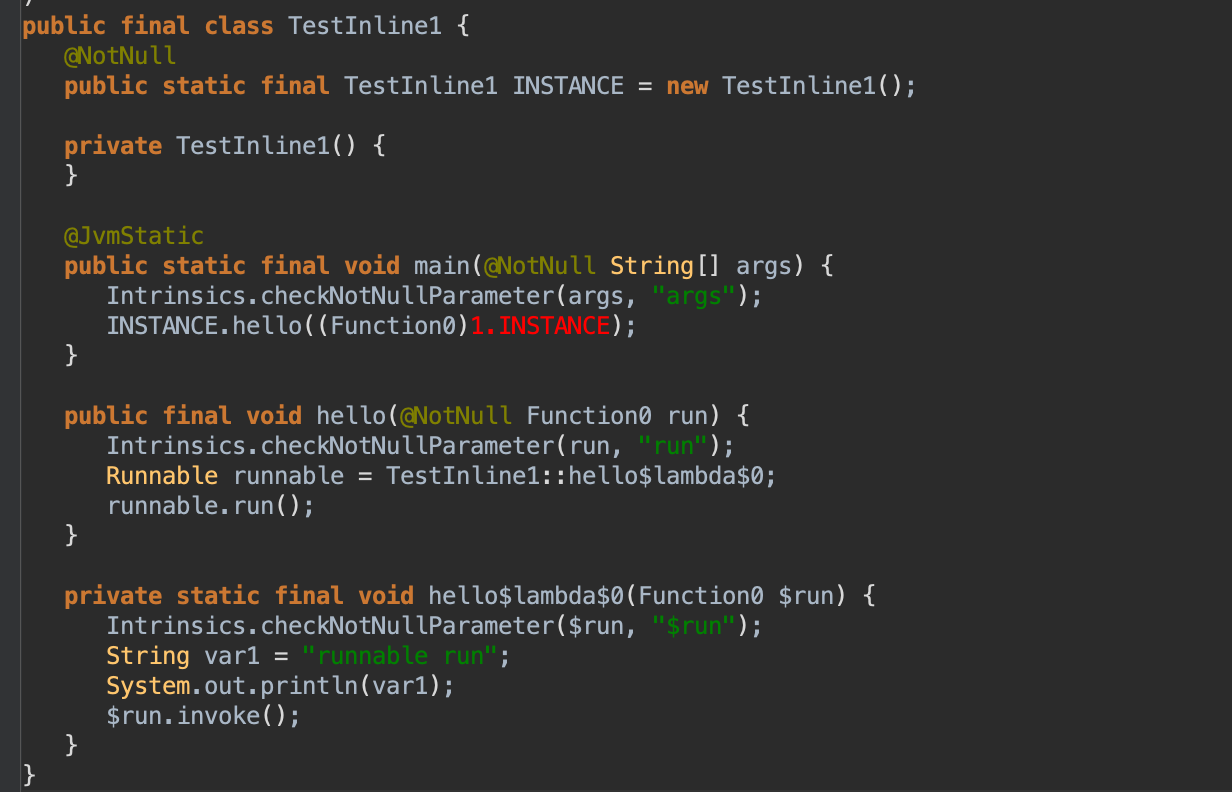 如果我把它作为内联函数来处理,如下:
对应的字节码如下:
如果我把它作为内联函数来处理,如下:
对应的字节码如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17object TestInline1 { @JvmStatic fun main(args: Array<String>) { hello { println("hello的闭包") } } inline fun hello(crossinline run: () -> Unit) { val runnable = Runnable { println("runnable run") run() } runnable.run() } }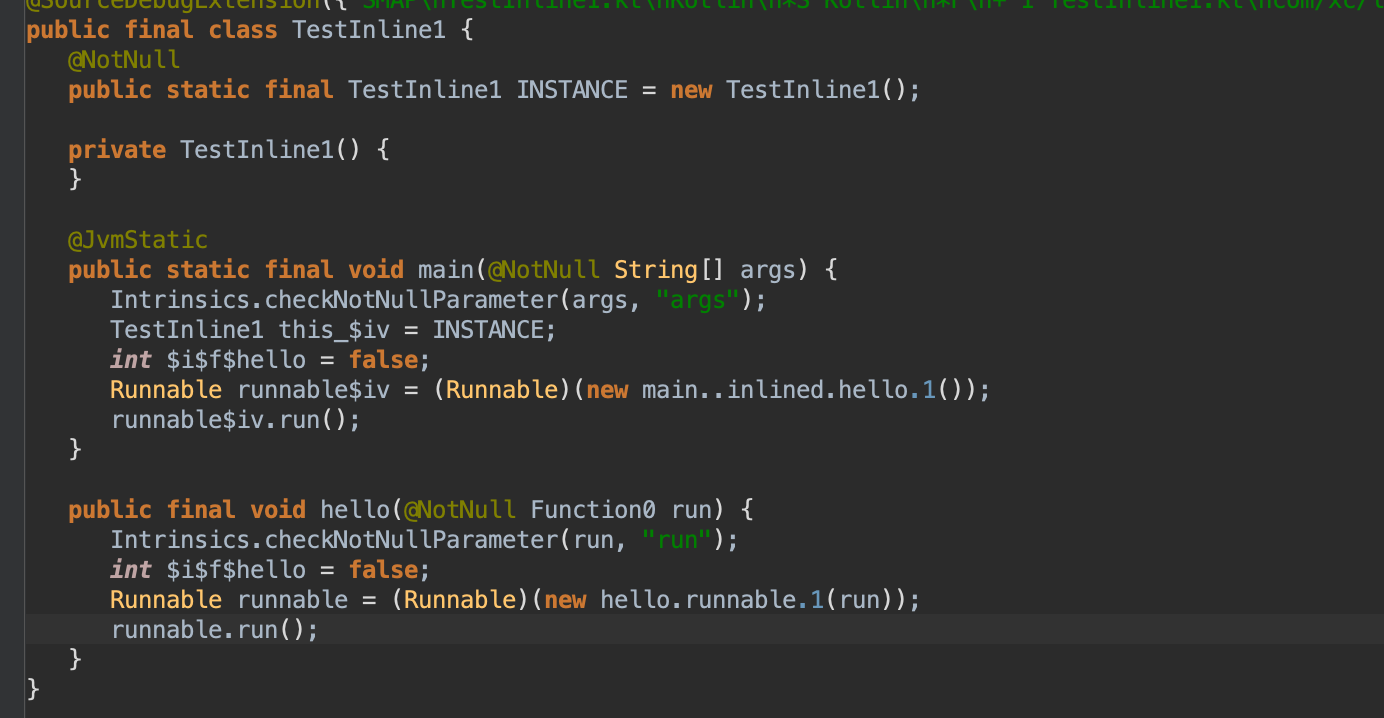
 可以看出来crossinline还是有内联效果,闭包直接在runnable中平铺开来了。
相关文档:https://juejin.cn/post/6869954460634841101
可以看出来crossinline还是有内联效果,闭包直接在runnable中平铺开来了。
相关文档:https://juejin.cn/post/6869954460634841101
java lambda和kotlin lambda区别
- 在java中如果使用匿名内部类的形式,在编译时它是会单独生成一个类,其中类名是「外部类名$index.class」这种形式。如果使用lambda的形式,它不会在编译时单独生成一个类,它是执行了invokedynamic指令,在运行时动态生成lambda的类,其中类名是「外部类名$Lambda$index.class」这种形式。 参考:https://juejin.cn/post/7004642395060961310
- kotlin lambda它是在编译时看是否需要生成单独的类,如果是内联的时候就直接平铺代码,如果是非内联的时候才生成单独的类。
协程是怎么挂起的?怎么恢复的?
- 首先每一个协程代码块都会被编译成SuspendLambda对象,它也是一个Continuation对象,每次在执行到SuspendLambda的resume时候,都会去执行invokeSuspend方法,而该方法里面会去执行子协程,如果子协程返回COROUTINE_SUSPENDED状态的时候,父协程的resume方法会直接return了。当子协程执行完后,会通知父协程,此时父协程的的invokeSuspend方法再次被执行,而此时的状态机会发生变化,如果此时状态恢复后,会执行父协程中的Continuation,也就是父父协程的执行。
协程中的dispather是怎么指定在哪个线程上执行的?
首先dispather它是CoroutineContext(上下文)的一部分,在协程启动过程中,会取CoroutineContext中的CoroutineDispathcer部分。此时会构造一个DispathedContinuation对象,并把前面取到的Dispather传到DispathedContinuation中,此时会将DispathedContinuation扔到线程池中,最终会执行DispathedContinuation的run方法,在run里面会执行到SuspendLambda,也就是协程的代码块,最终会执行它的invokeSuspend方法。所以协程代码块中代码要执行在哪个线程是协程上下文的dispather部分指定的线程。 相关文档:https://www.xiangcman.fun/p/%E5%8D%8F%E7%A8%8B%E5%A6%82%E4%BD%95%E5%88%87%E6%8D%A2%E7%BA%BF%E7%A8%8B/
LinkedList特性
LinkedList继承自Deque,它是一个双端队列,允许在队列的两端插入和删除元素。可以作为栈(LIFO)或队列(FIFO)使用。基于链表(双向链表)实现,可以高效地插入和删除元素。 offer:给链表尾部插入元素,返回值表示是否插入成功 peek:取出头部节点,如果没有则返回null poll:取出头部节点,如果没有则返回null,取完后并把头部节点从队列中移除 remove:移除头部节点,如果没有头部节点则抛异常,有的话,则返回 push:给链表头部插入元素,没有返回值 pop:和remove一样的,都是移除头部节点,如果没有头部节点则抛异常,有的话,则返回
如果想实现队列的话,则使用offer和poll这一对方法;如果想实现栈的话,可以通过offerLast和pollLast来实现,或者通过offerFirst和pollFirst来实现。
ArrayDeque特性
它也是继承自Deque,和LinkedList的特性一样的,只不过ArrayDeque是通过数组实现的双端队列,内部用一个数组来放所有的节点,并且有两个int值用来存放头结点和尾结点的索引。并且ArrayDeque内部的默认节点容量是16个,也可以初始化容量大小。
区别:如果频繁要插入和删除操作,那么使用LinkedList,如果是查询情况比较多,可以优先使用ArrayDeque。
Pools.Pool
|
|
很明显这是一个对象池,SimplePool继承自Pool,并且可以指定对象池的大小。每次要回收的时候调用release,只有当前size小于对象池最大容量的时候才能回收,每次通过acquire来进行获取对象池中的元素。 其中在recyclerview动画篇章中,分析到InfoRecord对象中会使用Pools.SimplePool,InfoRecord存储的是ViewHolder在pre-layout阶段的坐标信息和post-layout阶段的坐标信息,以及ViewHolder的flag信息。因为ViewHolder的这些信息在动画处理过程中会频繁使用,所以此处使用了对象池来管理。
java中类加载机制
- 首先通过class的name查看有没有加载过,如果没有加载过,看自己的父类加载器是否存在,如果存在,则通过父类加载的loadClass去加载,如果不存在则说明当前类加载器是BootstrapClassLoader加载器,则通过BootstrapClassLoader去加载,如果还没有找到则通过自己的findClass去加载。整体过程理解为先让父类加载器去加载class,如果找不到则自己去加载。
- 类加载器分类:
- BootstrapClassLoader:最顶层的类加载器,它用来加载JAVA_HOME/jre/lib/rt.jar中的类
- ExtClassLoader:扩展类加载器,它用来加载JAVA_HOME/jre/lib/ext目录下的所有jar中的类,它的父加载器是BootstrapClassLoader,继承自URLClassLoader
- AppClassLoader:应用类加载器,它用来加载应用的类,也就是ClassPath,它的父加载器是ExtClassLoader,继承自URLClassLoader
- 自定义ClassLoader:用户实现,任意路径(如网络、文件),可以通过继承自ClassLoader或者是URLClassLoader
- 类加载器采用双亲委托模式来加载class,主要是为了系统的class的安全,优先使用系统的class来加载。
- 双清委托模式的核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0) sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } }
android中类加载机制
- android类加载机制也是按照双亲委托模型,但是可以通过自定义类加载器绕过双亲委派,实现类的隔离或复用
- 类加载器分类:
- BootClassLoader:系统类加载器,加载框架层的核心类(如 android.、java. 等系统类)
- PathClassLoader:应用类加载器,加载已安装 APK 中的类(即应用自身的类和 classes.dex),它的父类加载器是BootClassLoader,继承自BaseDexClassLoader,用于加载 /data/app/
/base.apk 中的代码,无法加载外部存储的dex、jar文件 - DexClassLoader:动态加载器,动态加载外部存储的 DEX/JAR 文件或 APK(如插件化、热修复场景),父加载器通常是PathClassLoader,也是继承自BaseDexClassLoader
- 上面提到android类加载也是通过双亲委托模式来加载类,但是安卓加载类是通过解析dex文件来加载的,所以对于PathClassLoader和DexClassLoader都是通过dex来加载class的,对于BootClassLoader,它仍然通过加载系统核心的DEX文件来实现类的加载,只不过这个过程是由虚拟机在底层直接处理的,不需要通过BaseDexClassLoader的DexPathList和DexFile机制。这种设计可能是为了优化系统启动速度和核心类的访问效率。
- BaseDexClassLoader完成了整个dex转换成class的过程,首先理解几个概念,
DexPathList,DexFile,Element:- DexPathList:被BaseDexClassLoader持有
- Element:被DexPathList持有,内部持有一个Element的数组
- DexFile:被Element持有
- DexPathList通过传入的dexPath,然后通过
;或:进行split,得到List:
从上面可以看出来,DexPathList里面会先split出dexPath,然后通过路径生成optimizedPath的路径,通过该路径生成DexFile对象,它就是表示一个dex文件。然后把DexFile塞入到Element数组中,最后该Element数组关联到BaseDexClassLoader中。 5. 接着看下如果通过dex加载到class,该处理是在BaseDexClassLoader中的findClass:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54//DexPathList.splitPaths private static List<File> splitPaths(String searchPath, boolean directoriesOnly) { List<File> result = new ArrayList<>(); if (searchPath != null) { for (String path : searchPath.split(File.pathSeparator)) { //省略代码 result.add(new File(path)); } } return result; } //DexPathList.makeDexElements private static Element[] makeDexElements(List<File> files, File optimizedDirectory, List<IOException> suppressedExceptions, ClassLoader loader) { Element[] elements = new Element[files.size()]; int elementsPos = 0; for (File file : files) { if (file.isDirectory()) { elements[elementsPos++] = new Element(file); } else if (file.isFile()) { String name = file.getName(); if (name.endsWith(DEX_SUFFIX)) { DexFile dex = loadDexFile(file, optimizedDirectory, loader, elements); elements[elementsPos++] = new Element(dex, null); } else { DexFile dex = loadDexFile(file, optimizedDirectory, loader, elements); if (dex == null) { elements[elementsPos++] = new Element(file); } else { elements[elementsPos++] = new Element(dex, file); } } } else { System.logW("ClassLoader referenced unknown path: " + file); } } if (elementsPos != elements.length) { elements = Arrays.copyOf(elements, elementsPos); } return elements; } //DexPathList.loadDexFile private static DexFile loadDexFile(File file, File optimizedDirectory, ClassLoader loader,Element[] elements) throws IOException { if (optimizedDirectory == null) { return new DexFile(file, loader, elements); } else { String optimizedPath = optimizedPathFor(file, optimizedDirectory); return DexFile.loadDex(file.getPath(), optimizedPath, 0, loader, elements); } }从上面可以看到BaseDexClassLoader最终是通过DexPathList->Element->DexFile->native来加载到class1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58//BaseDexClassLoader.findClass protected Class<?> findClass(String name) throws ClassNotFoundException { List<Throwable> suppressedExceptions = new ArrayList<Throwable>(); Class c = pathList.findClass(name, suppressedExceptions); if (c == null) { ClassNotFoundException cnfe = new ClassNotFoundException( "Didn't find class \"" + name + "\" on path: " + pathList); for (Throwable t : suppressedExceptions) { cnfe.addSuppressed(t); } throw cnfe; } return c; } //DexPathList.findClass public Class<?> findClass(String name, List<Throwable> suppressed) { for (Element element : dexElements) { Class<?> clazz = element.findClass(name, definingContext, suppressed); if (clazz != null) { return clazz; } } if (dexElementsSuppressedExceptions != null) { suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions)); } return null; } //Element.findClass public Class<?> findClass(String name, ClassLoader definingContext, List<Throwable> suppressed) { return dexFile != null ? dexFile.loadClassBinaryName(name, definingContext, suppressed) : null; } //DexFile.loadClassBinaryName public Class loadClassBinaryName(String name, ClassLoader loader, List<Throwable> suppressed) { return defineClass(name, loader, mCookie, this, suppressed); } //DexFile.defineClass private static Class defineClass(String name, ClassLoader loader, Object cookie, DexFile dexFile, List<Throwable> suppressed) { Class result = null; try { result = defineClassNative(name, loader, cookie, dexFile); } catch (NoClassDefFoundError e) { if (suppressed != null) { suppressed.add(e); } } catch (ClassNotFoundException e) { if (suppressed != null) { suppressed.add(e); } } return result; } //DexFile中的native方法 private static native Class defineClassNative(String name, ClassLoader loader, Object cookie,DexFile dexFile) throws ClassNotFoundException, NoClassDefFoundError;
android中Choreographer工作内容(android 29)
- 当某个view发起绘制(requestLayout或invalidate)的时候,会调用到ViewRootImpl的scheduleTraversals,该方法里面会给主线程的looper中的消息队列插入了一条消息屏障,接着给Choreographer插入了一条CALLBACK_TRAVERSAL类型的callback:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16void scheduleTraversals() { //如果没有发起绘制,才会往下走 if (!mTraversalScheduled) { mTraversalScheduled = true; //给主线程的looper中的消息队列插入了一条消息屏障 mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier(); //给Choreographer插入了一条CALLBACK_TRAVERSAL类型的callback mChoreographer.postCallback( Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null); if (!mUnbufferedInputDispatch) { scheduleConsumeBatchedInput(); } notifyRendererOfFramePending(); pokeDrawLockIfNeeded(); } } - 最终会走到Choreographer的scheduleFrameLocked,默认会走USE_VSYNC,并且默认该线程的looper是主线程的looper,走到如下逻辑,会走到scheduleVsyncLocked,最终会走到DisplayEventReceiver的native方法nativeScheduleVsync,表示监听底层的vsync信号,当vsync信号来的时候会回调onVsync方法,该方法会给主线程发送一条异步消息到消息队列中:
1 2 3 4 5 6 7 8 9 10//timestampNanos:VSync脉冲的时间戳 //frame:帧号码,自增 @Override public void onVsync(long timestampNanos, long physicalDisplayId, int frame) { mTimestampNanos = timestampNanos; mFrame = frame; Message msg = Message.obtain(mHandler, this); msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS); }- 可以看到onVsync中将自己(FrameDisplayEventReceiver)发送到任务队列中,并且执行时间是timestampNanos,说明该任务是要等到vsync信号指定的时间才会执行,它是一个runnable对象,到了执行该任务的时候会执行它的run方法,run方法会执行doFrame,任务队列是执行完上一个任务才会执行下一个任务,所以如果前面的任务一直阻塞着,doFrame其实不会在timestampNanos时间到了的时候,会立马执行的,看下doFrame处理逻辑:
doFrame主要是先看当前时间和期望的时间进行比较,得到延迟时间,如果该时间大于一帧所需要的时间(60hz刷新率的设备,那么一帧的时间是1000/60=16ms),并且该时间大于30帧的时间时候给出提示,这个时间跟view绘制的anr时间差不多。如果期望的时间比上一帧的时间还小,则说明上一帧还没结束,所以当前帧不处理,直接监听下一个vsync信号。接着就是处理各种callback(input、animation、traversal、commit)。而开头view发起绘制的时候,会插入一条traversal类型的callback,所以会执行到view的绘制流程。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50void doFrame(long frameTimeNanos, int frame) { final long startNanos; synchronized (mLock) { //期望的时间 long intendedFrameTimeNanos = frameTimeNanos; startNanos = System.nanoTime(); //当前时间-期望时间=延迟时间 final long jitterNanos = startNanos - frameTimeNanos; //延迟时间如果大于一帧所需要的时间 if (jitterNanos >= mFrameIntervalNanos) { final long skippedFrames = jitterNanos / mFrameIntervalNanos; //如果延迟执行的时间大于30帧的时间则给出提示 if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) { Log.i(TAG, "Skipped " + skippedFrames + " frames! " + "The application may be doing too much work on its main thread."); } final long lastFrameOffset = jitterNanos % mFrameIntervalNanos; //重新计算vsync信号来的时间 frameTimeNanos = startNanos - lastFrameOffset; } //如果期望的时间比上一帧的时间还小,则说明上一帧还没结束,所以当前帧不处理,直接监听下一个vsync信号 if (frameTimeNanos < mLastFrameTimeNanos) { scheduleVsyncLocked(); return; } mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos); mFrameScheduled = false; //给上一帧的时间附上标记 mLastFrameTimeNanos = frameTimeNanos; } try { Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame"); AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS); mFrameInfo.markInputHandlingStart(); //处理input类型的callback doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos); mFrameInfo.markAnimationsStart(); //处理animation类型的callback doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos); doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameTimeNanos); mFrameInfo.markPerformTraversalsStart(); //处理traversal类型的callback doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos); //处理commit类型的callback doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos); } finally { AnimationUtils.unlockAnimationClock(); Trace.traceEnd(Trace.TRACE_TAG_VIEW); } } - 当view发起绘制的时候,不会立马执行,而是先给Choreographer插入一条traversal类型的callback,同时让Choreographer监听下一个vsync信号的到来,当vsync信号来的时候,会给主线程的消息队列发送一条异步消息,当处理该消息的时候校验是否有掉帧处理,如果有掉30帧的时候,会给出提示,最后处理各种类型的callback。
vsync信号的作用
- VSync(垂直同步)在安卓屏幕刷新中的作用主要是协调屏幕刷新与图像渲染,避免画面撕裂并提升显示流畅度。具体作用如下:
- 防止画面撕裂
- 当屏幕刷新与图像渲染不同步时,可能出现画面撕裂。VSync通过同步两者的频率,确保屏幕在完整刷新一帧后再显示下一帧,从而避免这一问题。
- 提升流畅度
- VSync确保帧率与屏幕刷新率一致,减少帧率波动,使动画和滚动更加平滑。
- 优化性能
- VSync通过控制渲染节奏,避免GPU过度渲染,减少资源浪费,提升系统效率。
- 双缓冲与三缓冲
- VSync常与双缓冲或三缓冲结合使用。双缓冲通过交替使用前后缓冲区减少等待时间,而三缓冲进一步减少卡顿,提升性能。
- 减少延迟
- 虽然VSync可能增加少量延迟,但通过合理使用双缓冲或三缓冲,可以在保证流畅度的同时尽量降低延迟。
- 总结来说,VSync通过同步屏幕刷新与图像渲染,防止画面撕裂、提升流畅度、优化性能,并减少延迟。
- 防止画面撕裂
消息队列中的消息屏障
- 消息屏障主要是不处理屏障后面的同步消息,优先处理异步消息,实现原理是消息屏障本身是一个没有持有handler的消息,在获取消息的时候,如果发现队列头部是一个消息屏障,则不获取后面的同步消息,只获取后面的异步消息,一般作用于优先级比较高的场景,比如view的绘制流程。当处理完异步消息后,需要移除掉该消息屏障。
android中异常处理
首先理解下java中线程异常机制,如果线程中发生异常了,没有进行try-catch默认会抛给defaultUncaughtExceptionHandler的uncaughtException,而android中启动进程后会在RuntimeInit的commonInit方法中给主线程设置上defaultUncaughtExceptionHandler,对应的是KillApplicationHandler,在它的uncaughtException方法中先收集日志,然后kill掉进程。如果有设置线程的uncaughtExceptionHandler,那么此时java异常机制是就不走defaultUncaughtExceptionHandler了,所以不会走KillApplicationHandler,如果没有设置uncaughtExceptionHandler,而通过Thread.uncaughtExceptionHandler.uncaughtException(Exception)的时候,其实是先获取到线程的ThreadGroup,而在ThreadGroup中的uncaughtException中先看parent有没有,如果没有则也是回调到defaultUncaughtExceptionHandler中。
关于多张bitmap转成webp的原理
首先得理解webp是基于VP8/VP8L/VP9视频编码技术,支持有损压缩、无损压缩、透明度和动画。其内部格式基于RIFF(Resource Interchange File Format)文件结构,类似于WAV或AVI的容器格式。webp文件以RIFF头部开始,整体结构如下:
|
|
- RIFF:固定 4 字节标识符。
- FileSize:4 字节,表示文件总大小(包括 RIFF 头部和 WEBP 标签)。
- WEBP:固定 4 字节标识符,表明文件类型。
其中RIFF、FileSize、WEBP这三个归为header部分,chunks归为块部分。其中块可以分为如下部分:
- VP8/VP8L/VP9 图像数据块:
- VP8:用于有损压缩图像(类似 JPEG),块标识符为 VP8 (注意末尾空格)。
- VP8L:用于无损压缩图像(类似 PNG),块标识符为 VP8L。
- VP9:用于更高效的压缩(较少见),块标识符为 VP9 。
- VP8X(扩展元数据块):
- 标识符为 VP8X,用于存储扩展信息(如宽度、高度、动画标志、Alpha 通道等)。
- 必须出现在其他块之前(除 RIFF 和 WEBP 外)。
- 包含以下标志位:
- 动画(Animation)
- Alpha 通道(Alpha)
- EXIF 元数据
- XMP 元数据
- ICC 颜色配置文件
- ANIM(动画控制块):
- 标识符为 ANIM,仅用于动画 WebP。
- 包含背景颜色和循环次数。
- ANMF(动画帧块):
- 标识符为 ANMF,每个动画帧对应一个 ANMF 块。
- 包含帧的位置、时间延迟、宽度、高度等。 了解文件结构后,下面来介绍如何将多个bitmap生成webp:
- VP8/VP8L/VP9 图像数据块:
- 首先将bitmap压缩成webp格式的图片,按照50的压缩比,放到字节输入流中
- 读取webp的header部分
- 读取RIFF部分
- 读取文件大小
- 读取WEBP部分
- 读取第一个带有playload的chunk块
- 由于前面指定了bitmap转webp的时候是有损,因此读取chunk的时候直接去读WP8块,接着读取它的payload信息,playload大小就是chunk大小,4字节。
- 读取完后,接着就是写入到输出流中,判断如果是第一个bitmap,则创建header部分,其中header也是按照RIFF、FileSize、WEBP三个区域写回,接着写入VP8X数据块,标明宽高、动画、通道、元数据等信息。接着创建ANIM动画控制块,标明背景颜色和循环次数。最后创建每一个bitmap对应的ANMF动画帧块,将指定每一帧的的尺寸、时长playload数据。
kotlin中==和===区别
kotlin中的==:如果是对象类型,比较的是equals方法;如果是基本类型,比较的是值。 kotlin中的===:如果是对象类型,比较的是内存地址,指向的是不是同一个对象;如果是基本类型。比较的还是值。
kotlin中lazy的原理
Lazy本身是一个接口,会提供一个value属性和isInitialized的方法,注意了在kotlin接口中提供属性,其实对应java中的get**方法,平时写的by lazy{},去定义一个属性的时候,其实它是一种属性委托的写法,但是lazy它是只读的委托模式,所以在定义属性的时候必须用val来修饰变量。当我们去读取lazy的变量的时候,实际是调用了前面定义的value属性,对应java代码其实是getValue方法,当首次去获取属性的时候,发现_value为空,所以会通过闭包去获取,获取到后会将返回值给到_value,下次再调用getValue的时候,直接返回该_value。
|
|
-
第一个参数lock是可以传入对象锁
-
第二个参数是传进来的闭包,是非空
-
返回值:实际是一个SynchronizedLazyImpl对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28private class SynchronizedLazyImpl<out T>(initializer: () -> T, lock: Any? = null) : Lazy<T>, Serializable { private var initializer: (() -> T)? = initializer //使用Volatile关键字修饰_value变量,在多线程下能达到可见性的效果 @Volatile private var _value: Any? = UNINITIALIZED_VALUE // final field is required to enable safe publication of constructed instance private val lock = lock ?: this//如果传进来的对象锁为空,则当前对象作为锁 override val value: T get() { val _v1 = _value if (_v1 !== UNINITIALIZED_VALUE) { @Suppress("UNCHECKED_CAST") return _v1 as T } //通过synchronized来保证创建对象是原子操作 return synchronized(lock) { val _v2 = _value if (_v2 !== UNINITIALIZED_VALUE) { @Suppress("UNCHECKED_CAST") (_v2 as T) } else { val typedValue = initializer!!() _value = typedValue initializer = null typedValue } } } }综上来看,lazy默认是线程安全的,默认使用的对象锁是当前lazy对象,也可以自己传入锁对象。使用Volatile来保证对象的可见性,通过synchronized保证创建对象是原子操作。
kotlin委托模式
- 属性委托:允许你把属性的getter、setter逻辑委托给一个独立的对象来管理
- 通过「var 属性 by 委托类」的形式定义一个属性委托的过程,当使用var的时候,说明该属性能可读和可写,在属性写的时候实际编译器会去调委托类的setValue方法,当属性读的时候实际编译器会去调委托类的getValue方法。
实际对应的字节码:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18class Delegate { operator fun getValue(thisRef: Any?, property: KProperty<*>): String { return "属性 ${property.name} 被代理了" } operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) { println("属性 ${property.name} 赋值为 $value") } } class Example { var message: String by Delegate() } fun main() { val e = Example() println(e.message) // 访问时调用 getValue() e.message = "Hello" // 赋值时调用 setValue() }1 2 3 4 5 6 7class Example { private val message$delegate = Delegate() // 委托对象变为一个私有属性 var message: String get() = message$delegate.getValue(this, ::message) set(value) = message$delegate.setValue(this, ::message, value) }- by Delegate() 其实是 Kotlin 编译器生成的 get() 和 set() 方法。
- getValue() 和 setValue() 由 Delegate 这个委托对象实现。
- 类委托:允许一个类 将实现某个接口的功能委托给另一个对象,减少代码重复。
- by 关键字 可以让 Kotlin 自动生成委托方法,避免手写重复代码
上面的ProxyPrinter被编译器编译为如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17interface Printer { fun printMessage() } class RealPrinter : Printer { override fun printMessage() { println("RealPrinter: 打印内容") } } class ProxyPrinter(printer: Printer) : Printer by printer fun main() { val realPrinter = RealPrinter() val proxy = ProxyPrinter(realPrinter) proxy.printMessage() // 调用的是 realPrinter 的方法 }1 2 3 4 5 6 7class ProxyPrinter(printer: Printer) : Printer { private val printerDelegate: Printer = printer override fun printMessage() { printerDelegate.printMessage() } }- by printer 让 ProxyPrinter 自动实现 Printer 接口的方法,而不需要手动实现。
- 编译器在字节码层面会自动插入代理方法,提高代码简洁性。
- 属性委托:允许你把属性的getter、setter逻辑委托给一个独立的对象来管理
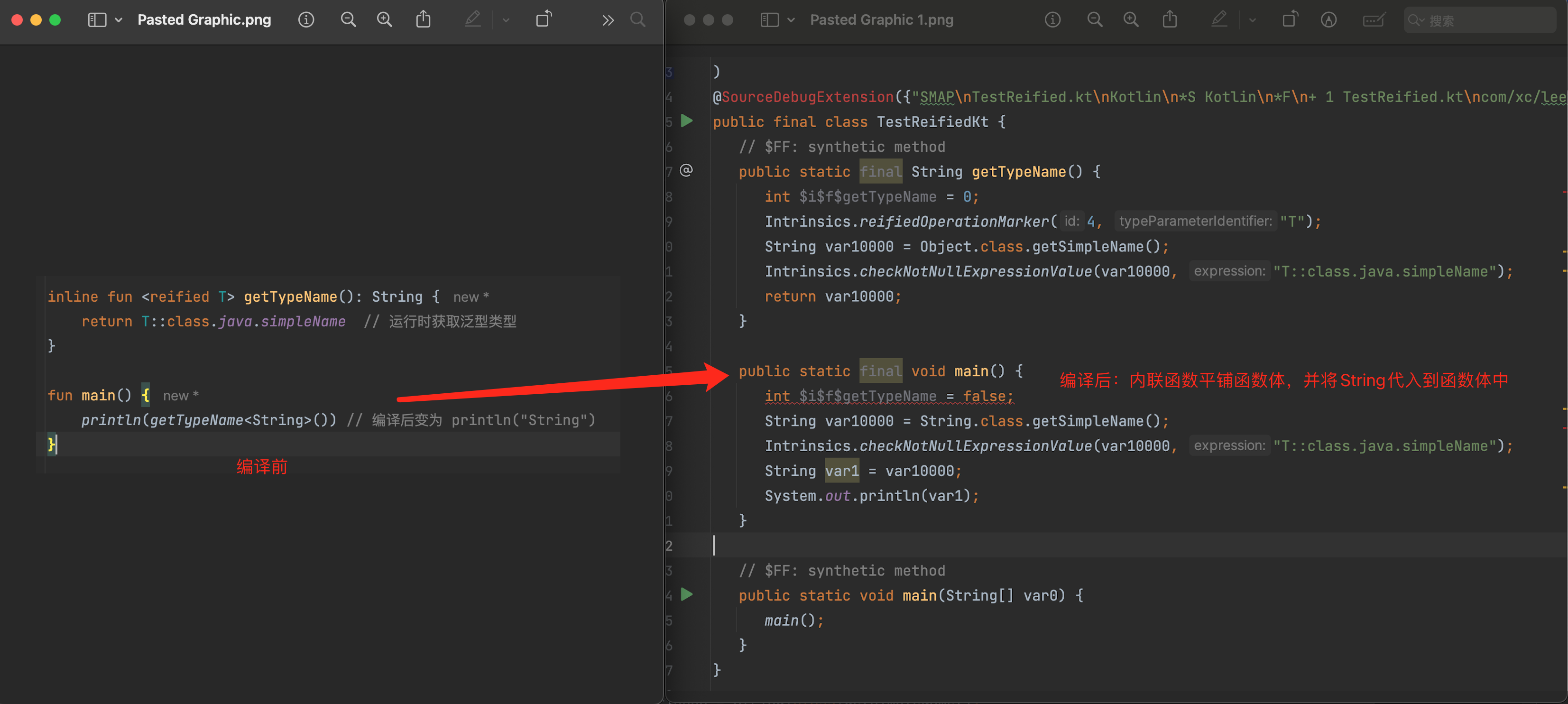
为什么reified必须和inline一起使用?
reified关键字是用来修饰泛型,而泛型在编译后会被擦除掉,所以如果要在运行时获取到泛型的类型,就得用reified关键字,而inline的作用是修饰方法内联,之前讲内联函数的特点是将函数体平铺到调用处。那它两有什么联系呢?先来看一个例子:
 此处提示我,使用reified关键字来修饰泛型,因为泛型在编译后,会被擦除掉,所以是获取不到它的类型,只有添加reified才能保证它的类型存在。那添加完reified后提示为什么还要添加inline呢?
这是因为只有内联函数将函数体进行平铺,然后将泛型通过「真类型」代入到函数体中,看下编译后的代码:
此处提示我,使用reified关键字来修饰泛型,因为泛型在编译后,会被擦除掉,所以是获取不到它的类型,只有添加reified才能保证它的类型存在。那添加完reified后提示为什么还要添加inline呢?
这是因为只有内联函数将函数体进行平铺,然后将泛型通过「真类型」代入到函数体中,看下编译后的代码:
关于viewModel的一些思考
- 创建:默认都是通过ViewModelProvider的get方法获取到viewModel,里面通过factory(工厂方法模式)的create来创建viewModel,创建完之后会把viewModel保存到ViewModelStore中。ViewModelStore实际是用一个hashMap来存储viewModel,key是viewModel的class name拼上前缀,value就是当前viewModel。android中默认的factory是ViewModelProvider.AndroidViewModelFactory,在它的create方法里面通过前面传进来的viewModel的class反射创建viewModel。
- 存储:像平时写的activity都是继承自
ComponentActivity,它是实现了ViewModelStoreOwner接口,该接口需要持有一个ViewModelStore,ViewModelStore是在ensureViewModelStore方法中创建的:getLastNonConfigurationInstance()方法是获取Activity中的mLastNonConfigurationInstances属性的activity属性,结构如下:1 2 3 4 5 6 7 8 9 10 11 12 13void ensureViewModelStore() { if (mViewModelStore == null) { NonConfigurationInstances nc = (NonConfigurationInstances) getLastNonConfigurationInstance(); if (nc != null) { // Restore the ViewModelStore from NonConfigurationInstances mViewModelStore = nc.viewModelStore; } if (mViewModelStore == null) { mViewModelStore = new ViewModelStore(); } } }第一次打开activity的时候mLastNonConfigurationInstances属性是空的,因此在ensureViewModelStore中是直接创建了ViewModelStore。那什么时候mLastNonConfigurationInstances不为空呢?我们注意到mLastNonConfigurationInstances是在activity的attach中赋值的,它的上级来源是ActivityClientRecord中的lastNonConfigurationInstances属性,那什么时候给ActivityClientRecord的lastNonConfigurationInstances属性赋值呢?这个可以在aosp中的1 2 3 4 5 6 7static final class NonConfigurationInstances { Object activity; HashMap<String, Object> children; FragmentManagerNonConfig fragments; ArrayMap<String, LoaderManager> loaders; VoiceInteractor voiceInteractor; }frameworks/base/core/java/android/app/Activity.java类中的performDestroyActivity方法中找到:而activity的retainNonConfigurationInstances方法中会组装NonConfigurationInstances中的activity属性,是通过onRetainNonConfigurationInstance方法来收集的:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15void performDestroyActivity(ActivityClientRecord r, boolean finishing, boolean getNonConfigInstance, String reason) { Class<? extends Activity> activityClass; if (getNonConfigInstance) { try { //通过调用activity的retainNonConfigurationInstances方法来给ActivityClientRecord的lastNonConfigurationInstances属性赋值 r.lastNonConfigurationInstances = r.activity.retainNonConfigurationInstances(); } catch (Exception e) { if (!mInstrumentation.onException(r.activity, e)) { throw new RuntimeException("Unable to retain activity " + r.intent.getComponent().toShortString() + ": " + e.toString(), e); } } } }onRetainNonConfigurationInstance方法的调用是在1 2 3 4 5 6NonConfigurationInstances retainNonConfigurationInstances() { Object activity = onRetainNonConfigurationInstance(); NonConfigurationInstances nci = new NonConfigurationInstances(); nci.activity = activity;//手机activity属性 return nci; }ComponentActivity中实现了:可以看到最终viewModelStore通过ComponentActivity中的NonConfigurationInstances存储起来了,最终被ActivityClientRecord持有。当横竖屏切换的时候会触发ActivityThread的handleRelaunchActivity,在该方法里面会先将activity的lastNonConfigurationInstances保存到ActivityClientRecord,等到创建activity的时候会把lastNonConfigurationInstances给到activity,所以viewmodelStore此时拿到的还是之前的。1 2 3 4 5 6 7 8 9@Override @Nullable @SuppressWarnings("deprecation") public final Object onRetainNonConfigurationInstance() { ViewModelStore viewModelStore = mViewModelStore; NonConfigurationInstances nci = new NonConfigurationInstances(); nci.viewModelStore = viewModelStore; return nci; }- fragment中的viewModel是怎么存储的?
- fragment也是实现了viewModelOwner接口,所以它也有自己的viewModelStore,它的viewModelStore是通过FragmentManagerViewModel来管理的,FragmentManagerViewModel的创建是看当前fragment有没有parentFragment,如果有,则通过parentFragment的fragmentManager的getChildNonConfig方法来获取。如果parent为空,则通过activity的viewModelStore来创建。所以fragment的viewModelStore存储也是依赖于activity,因为最终该FragmentManagerViewModel是通过activity的viewModelStore来存储的。
- fragment中的viewModel是怎么存储的?
LiveData的一些思考
- liveData是基于监听lifecycle生命周期的数据驱动框架,在lifecycle为STARTED才会触发触发数据驱动,并且在lifecycle为DESTROYED的时候自动解绑observer。
- 比如我在lifecycle的CREATED状态给livedata灌数据,等到lifecycle状态为STARTED的时候就会给livedata的observer给发送数据。
- 当提前给livedata灌输数据的时候,但是此时还没添加observer,等到添加observer的时候,会自动把数据分发到observer中了。这个就是数据倒灌。主要是因为给livedata发送数据的时候,livedata中的版本号会+1,但是新添加的observer此时的版本号还是-1,所以在注册的时候,会把数据分发给observer。通常数据倒灌的解决方案是:
- 每次在添加observer的时候,反射将livedata中的版本号给置为0
- 重写livedata,然后添加一个已经注册的标记(AtomicBoolean),第一次调用observe的时候才会给该标记置为非空。此时在发送数据的时候判断如果该标记不为空,才会置为true,在observe的地方通过包装一个observer,只有该标记置为true了,才会给到目标observer传递数据。(这种方案只适合添加单observer的场景,如果多observer就不适合了)
- 继承livedata,用一个map记录observer是否接收过消息,如果接收过了就不能再接收
- livedata中的getVersion方法是包内可见的,因此我们可以新建和livedata同样的包名的类,这样就能访问getVersion方法,然后在observe方法中判断如果version>START_VERSION才会能消费事件
- livedata中setValue是同步方法,是线程不安全的。postValue在一个线程的时候,如果发送数据比较频繁的时候,只会把最后一个数据发送给observer,因为postValue是通过给主线程的消息队列发送数据,然后发送给observer。在多线程情况下虽然设置数据是加了同步块,但是因为还是给主线程的消息队列发送消息来切换线程,导致前面的数据会被后面的数据给覆盖。
glide缓存
- glide缓存分为内存和硬盘两类,其中内存缓存又分为活跃缓存和LRU缓存,硬盘缓存分为解码后按照view尺寸展示的bitmap缓存,另外一部分是原始图片的缓存。
- 活跃缓存:它的结构是一个hashmap,其中key是按照url、尺寸等信息拼成的,value是一个弱引用对象,其中弱引用中放的才是图片缓存对象。
- LRU缓存:它底层是一个LRU策略的缓存,key也是和上面活跃缓存用的是同一个。value存的是解码后的图片缓存。
- 解码后的硬盘缓存:也是使用的LRU策略的缓存,其中key是按照指定尺寸来构建的,然后从DiskLruCache中获取缓存。
- 原始图片的硬盘缓存:也是使用的LRU策略的缓存,其中key不是通过指定尺寸来构建的,然后也是从DiskLruCache中获取缓存。
- 缓存获取步骤:

- LRU的内存缓存是在什么存储的?
- 从上面流程图来看每次从非活跃缓存中获取到图片缓存后,都会放入到活跃缓存中,那什么时候会放到内存的LRU缓存中呢?当view触发onViewDetachedFromWindow的时候,也就是当前view销毁后,会查看当前view绑定的图片被正在使用标记的次数,如果次数为0了,则将当前图片加入到LRU的内存缓存中。
- glide为什么要设计两层的内存缓存?
- 内存缓存分为活跃的缓存,它是一个map数据结构,value存储的是弱引用包装了缓存数据,另外一层是LRU级别的缓存。活跃数据指的是当前正在使用的资源,比如正在显示的图片,这部分用弱引用来保存,这样当图片不再被使用时,垃圾回收器可以自动回收,避免内存泄漏。而LRU缓存则是最近最少使用的缓存,使用强引用,当内存不足时,会移除最久未使用的资源。
- 如果只有LRU缓存的时候,正在使用的图片可能是长时间没有被访问的图片,而此时如果只有LRU缓存的时候,可能会把正在使用的图片缓存给移除掉了,这样的话,当再使用该图片的时候,会从磁盘中去获取该图片,这样增大了获取图片的时间。如果只有弱引用缓存的时候,此时图片不被使用了,被GC给回收了,那此时也只能从磁盘中获取,增大了获取图片的时间。如果此时有LRU缓存,能在内存中保留一段时间,降低从磁盘中读取的可能。
kotlin中Sequence和普通集合的区别
Sequence原理是持有了原有集合的iterator,在等到调用toList的时候,才会拿到Sequence的iterator进行遍历,然后添加到新的集合中。中间的操作符都会生成一个新的sequence,然后每遍历一个元素都会去执行一次中间操作符的iterator的next方法,然后将结果给到下一个sequence,最后添加到新的集合中。 优点:相较于普通的集合,它是惰性执行中间操作符,并且中间的操作符只是通过iterator进行迭代每一个元素,而普通的集合是每一个操作符会新生成一个集合,导致内存会增高。Sequence的使用场景是中间操作符比较多的情况下进行使用,不会增加新的集合,并且是惰性遍历元素。 比如下面这个操作:
|
|
在调用toList时候,才会执行上面的map和filter方法,并且map和filter遍历元素的时候,是每个元素依次调用到map和filter,中间是通过sequence的iterator进行遍历,不会产生中间的集合。 日志如下:
|
|
再来看下普通集合的操作:
|
|
上面的map和filter是分开执行的,不会等到最后才执行,所以没有惰性,map和filter都会产生新的集合,并且在遍历元素的时候,每一个操作符是先遍历完每一个元素,然后才执行下一个操作符的遍历。 日志如下:
|
|
kotlin中Sequence和集合的Stream区别
Stream是java1.8之后出的语法,和Sequence一样支持流式和惰性的特点,它在遍历元素的时候也是每个元素都会按顺序经过中间的操作符,不像普通的集合那样每个元素必须先执行完一个操作符,然后才进行下一个操作符。但是Stream只能一次性消费,消费完后,就不能再使用该stream。而Sequence可以多次使用。同时Stream的parallelStream方法支持并发处理,遍历元素的时候,不是按照元素会顺序执行每一个操作符,当数据量大的时候可以考虑使用parallelStream。
companion object和object中定义变量
在companion object定义非const变量的时候,会在Companion内部类中提供get方法,在外部类中定义该常量:
|
|
生成的class代码如下:
|
|
如果kotlin代码如下:
|
|
对应class代码如下:
|
|
在有const的时候,不会在Companion内部类中提供get方法。只会在外部类提供公开类型的常量。 如果在object类中定义const变量,如下:
|
|
会生成如下class:
|
|
如果去掉const会生成如下class:
|
|
从上面伴生对象和object类发现伴生对象会生成内部类,并通过饿汉式生成单例。object是在内加载的时候生成单例。
记录一次gradle编译问题
- 问题:在添加某个广告sdk后,发现工程中编译会报错,报错信息如下:
- Caused by: org.jetbrains.kotlin.gradle.tasks.CompilationErrorException: Compilation error. See log for more details
- ‘onNewIntent’ overrides nothing
- 该问题说activity的子类(kotlin类)中出现了onNewIntent方法中的intent参数定义可为空了,就增加了一个广告的sdk后,怎么就提示intent要定义成不为空的呢。既然是广告sdk导致的,那么下面就按照依赖关系把问题找到,执行gradle的命令如下:
上面命令会找到app依赖的所有module的间接依赖,并输出到文件中,直接看新增的广告sdk的module信息:
1./gradlew app:dependencies --configuration debugRuntimeClasspath > dependencies.txt可以看到,在广告sdk中会把activity-ktx的版本从1.7.1升级到1.9.2,继续顺藤摸瓜,发现在1.9.2的版本中1+--- androidx.activity:activity-ktx:1.7.1 -> 1.9.2 (*)ComponentActivity,会给onNewIntent方法的intent参数加上了@Suppress("InvalidNullabilityOverride")注解,而在1.7.1版本中是加上@SuppressLint({"UnknownNullness", "MissingNullability"})注解。通过Gemini对比两者的区别,最终得出结论:- @Suppress(“InvalidNullabilityOverride”)
- 如果一个 Java 方法的参数是 String param,Kotlin 编译器可能无法确定它是可空 (String?) 还是非空 (String)。如果你将其重写为 param: String?(可空),但 Kotlin 编译器内部推断它应该是 String(非空),或者反之,就会触发 InvalidNullabilityOverride 警告。
@SuppressLint({"UnknownNullness", "MissingNullability"})- 它是lint中的注解,用于抑制 Lint 工具发出的特定警告或错误。UnknownNullness:当 Lint 工具无法确定某个变量、参数或返回类型的空安全性时(通常是因为它来自没有空安全注解的 Java 代码或第三方库),它会发出此警告,提醒你其空安全性是未知的。MissingNullability:当 Lint 认为某个地方应该有空安全注解(@NonNull 或 @Nullable),但却缺失了时,它会发出此警告。这通常发生在你在编写 Java 代码,但没有为参数或返回类型明确添加空安全注解时。
- 目的: 告诉 Lint 工具:“我已经意识到这里存在空安全注解缺失或未知空安全性的问题,但我有理由不添加注解或接受当前状态,请不要再警告我。”
- 从上面分析可知,而activity中的onNewIntent方法中确实没有任何非空和可空的注解,在1.7.1版本中通过lint注解来告诉lint,这里的intent参数是不可确定的空参数,不需要发出警告。而在1.9.2版本中强制要求子类中必须为非空的,因此当之前的子类是可空的时候,就会出现前面所说的编译问题
- @Suppress(“InvalidNullabilityOverride”)
- 方案:直接在添加广告sdk的地方,排除掉activity-ktx的依赖:
1exclude group: "androidx.activity", module: "activity-ktx"