booster是基于gradle transform、asm进行字节码操作的框架,内部有很多gradle transform来操作对应的字节码,首先我们将对应的插件依赖进来,我们以toast插件替换为测试,看下效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
buildscript {
ext {
plugin_version = "0.3.0"
booster_version = "1.0.0"
}
// ext.plugin_version = "0.3.0"
repositories {
google()
jcenter()
maven {
url "https://artifact.bytedance.com/repository/byteX/"
}
}
dependencies {
classpath 'com.android.tools.build:gradle:3.5.3'
//booster
classpath "com.didiglobal.booster:booster-gradle-plugin:$booster_version"
//booster toast插件
classpath "com.didiglobal.booster:booster-transform-toast:$booster_version"
//bytex base
// classpath "com.bytedance.android.byteX:base-plugin:${plugin_version}"
// Add bytex plugins' dependencies on demand. 按需添加插件依赖
// classpath "com.bytedance.android.byteX:method-call-opt-plugin:${plugin_version}"
// NOTE: Do not place your application dependencies here; they belong
// in the individual module build.gradle files
}
}
|
然后使用插件:
1
2
|
apply plugin: 'com.android.application'
apply plugin: 'com.didiglobal.booster' // ③
|
在MainActivity中添加如下代码:
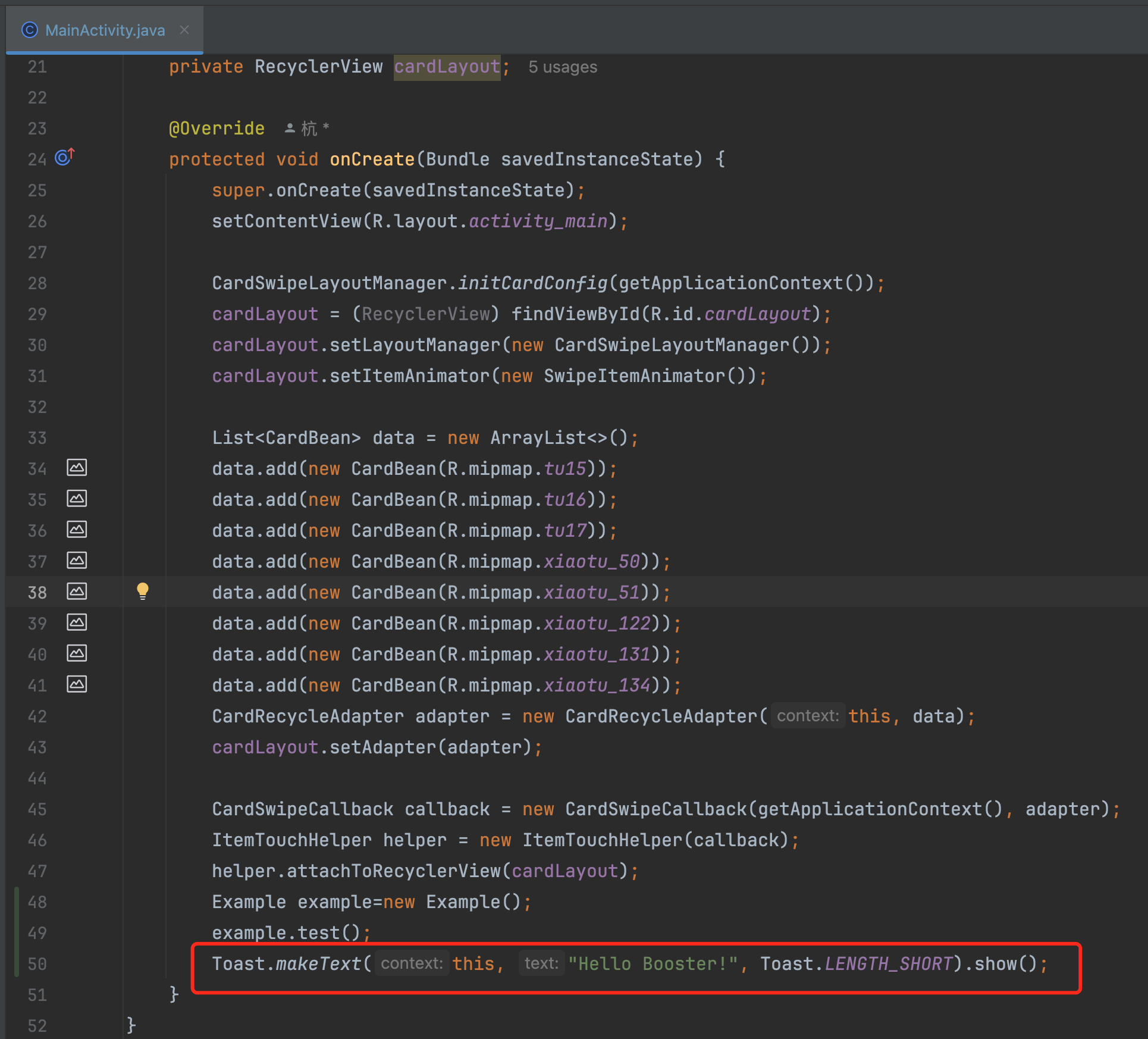 然后看编译后的类,这里有个细节,大家得熟悉打包流程,javac编译成class后,然后把class转化成dex文件,transform就是作用于class转成dex之间,所以如果看javac之后的class是看不到最终toast插件作用的效果,需要反编译看最终的apk或者dex文件:
然后看编译后的类,这里有个细节,大家得熟悉打包流程,javac编译成class后,然后把class转化成dex文件,transform就是作用于class转成dex之间,所以如果看javac之后的class是看不到最终toast插件作用的效果,需要反编译看最终的apk或者dex文件:
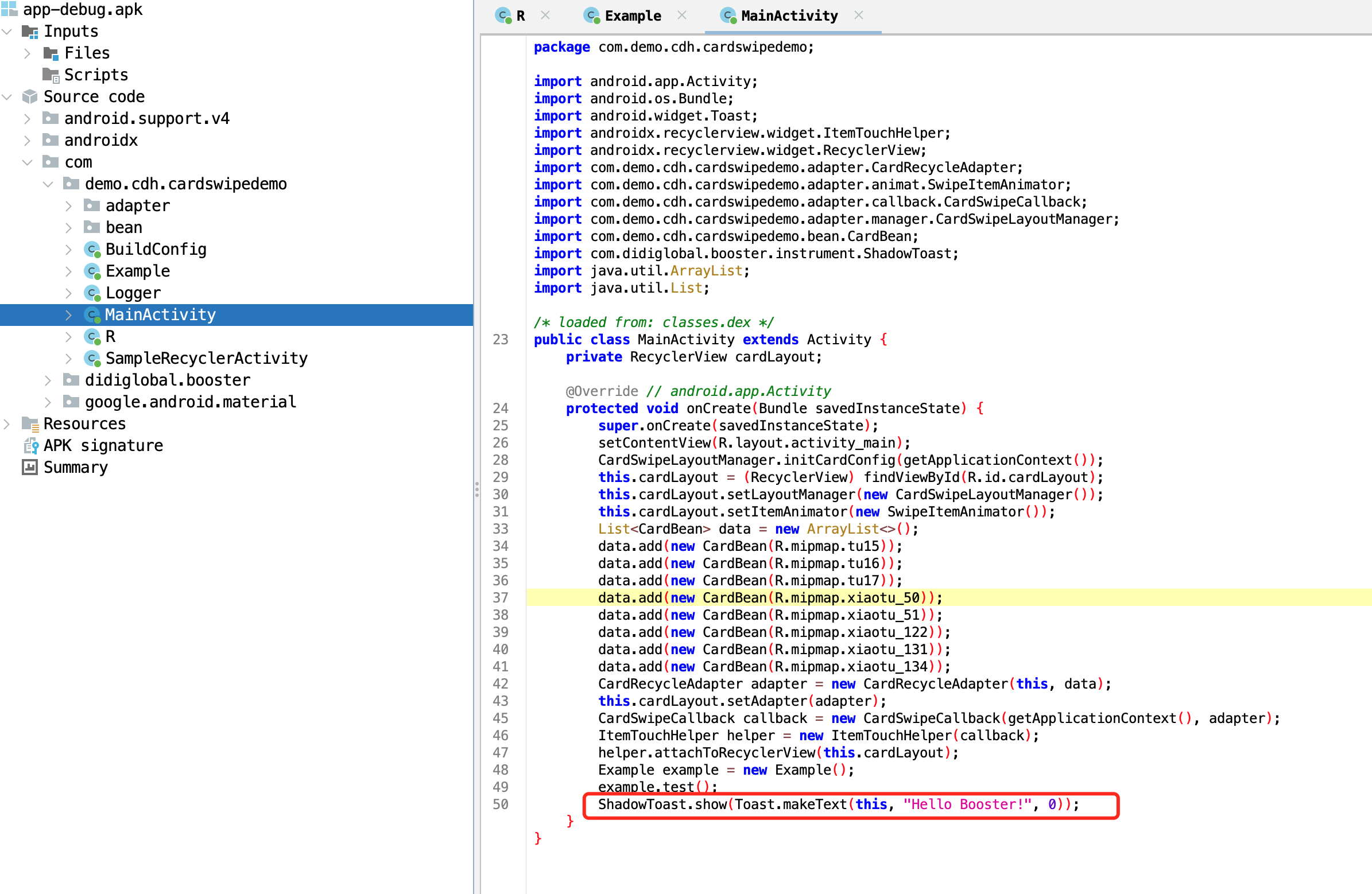 可以看到此时是替换成了ShadowToast中的show方法了。下面结合源码看下booster如何做到class替换的,本次通过gradle下载的插件源码来分析,booster插件下载的地址在
可以看到此时是替换成了ShadowToast中的show方法了。下面结合源码看下booster如何做到class替换的,本次通过gradle下载的插件源码来分析,booster插件下载的地址在/Users/xiangcheng/.gralde/cache/modules-2/files-2.1/com.didiglobal.booster下:
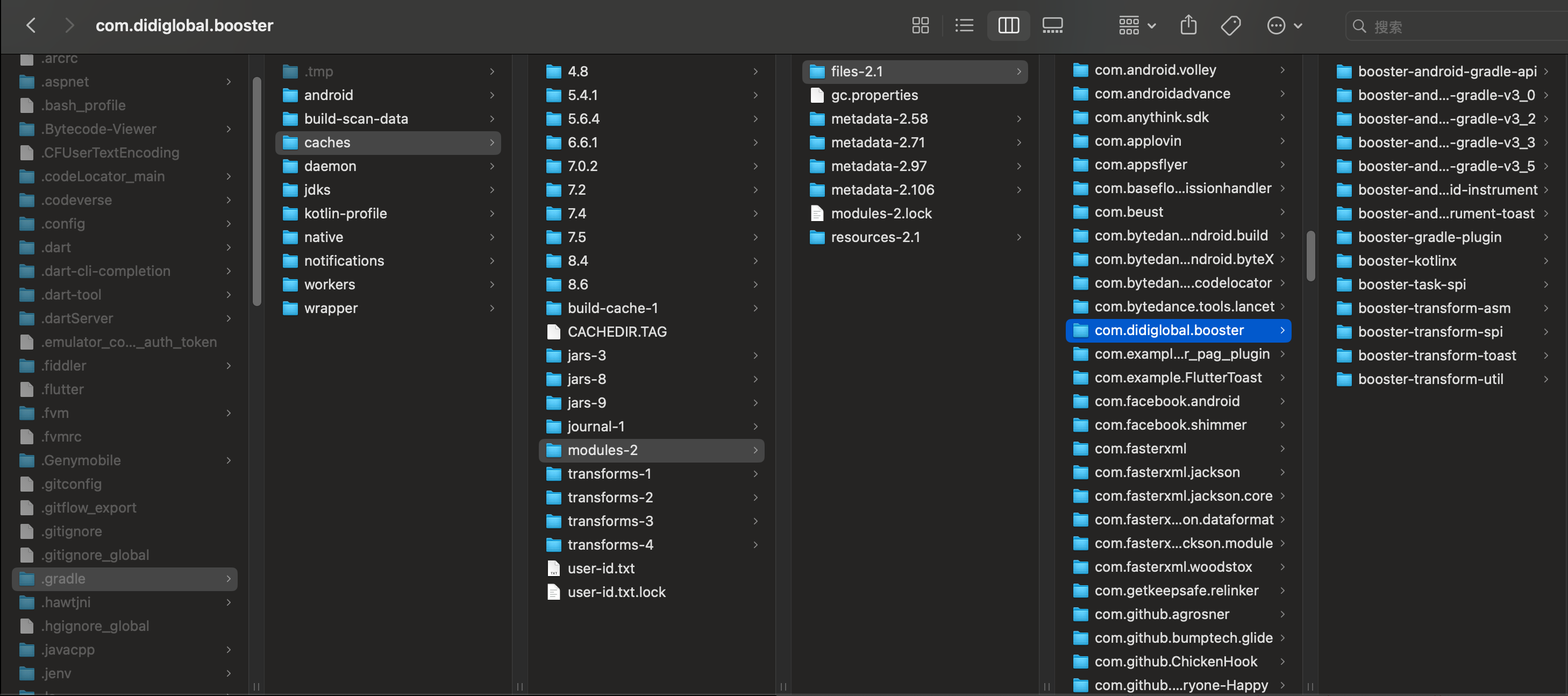
booster-gradle-plugin
是booster定义插件的模块,下面打开它的源码,找到它的plugin:
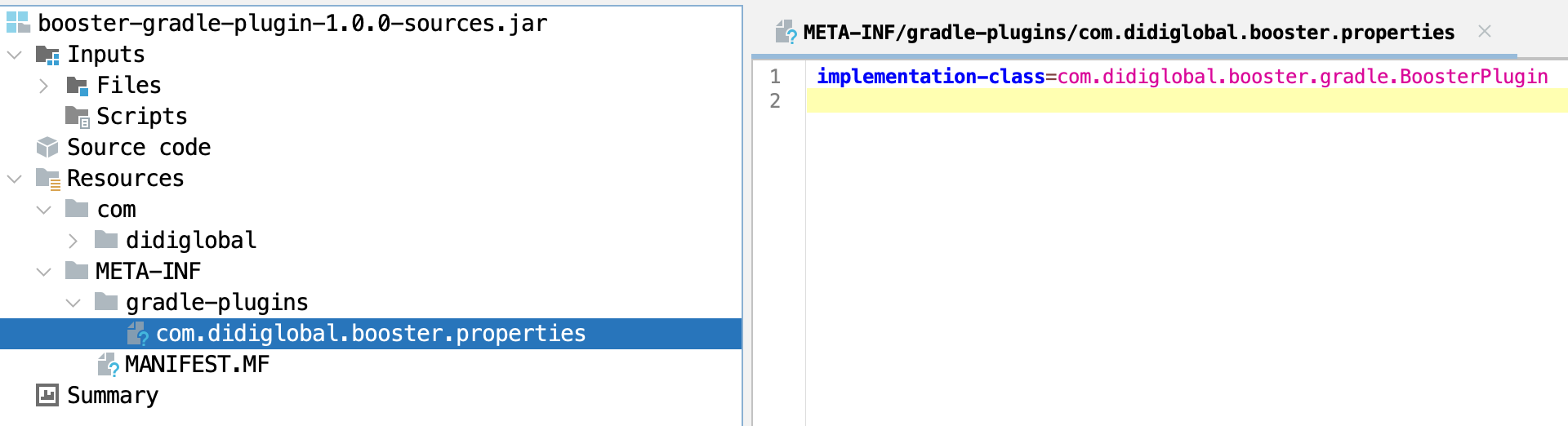 booster插件对应的类名是
booster插件对应的类名是com.didiglobal.booster.gradle.BoosterPlugin:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
package com.didiglobal.booster.gradle
import com.android.build.gradle.AppExtension
import com.android.build.gradle.LibraryExtension
import com.didiglobal.booster.task.spi.VariantProcessor
import org.gradle.api.Plugin
import org.gradle.api.Project
import java.util.ServiceLoader
/**
* Represents the booster gradle plugin
*
* @author johnsonlee
*/
class BoosterPlugin : Plugin<Project> {
override fun apply(project: Project) {
when {
//如果依赖booster插件的module是application类型
project.plugins.hasPlugin("com.android.application") || project.plugins.hasPlugin("com.android.dynamic-feature") -> project.getAndroid<AppExtension>().let { android ->
//注册BoosterAppTransform
android.registerTransform(BoosterAppTransform())
//project.afterEvaluate监听module配置阶段完成后
project.afterEvaluate {
//通过ServiceLoader来找到所有的VariantProcessor子类,它是spi模块中定义的
ServiceLoader.load(VariantProcessor::class.java, javaClass.classLoader).toList().let { processors ->
//首先遍历应用中所有的变体
android.applicationVariants.forEach { variant ->
//遍历所有的VariantProcessor,把变体传到VariantProcessor的process方法中
processors.forEach { processor ->
processor.process(variant)
}
}
}
}
}
//如果依赖booster插件的module是library类型
project.plugins.hasPlugin("com.android.library") -> project.getAndroid<LibraryExtension>().let { android ->
//BoosterLibTransform
android.registerTransform(BoosterLibTransform())
project.afterEvaluate {
ServiceLoader.load(VariantProcessor::class.java, javaClass.classLoader).toList().let { processors ->
android.libraryVariants.forEach { variant ->
processors.forEach { processor ->
processor.process(variant)
}
}
}
}
}
}
}
}
|
我们只看当前module是application类型的,library类型的module处理基本一致。首先注册BoosterAppTransform,然后监听project配置阶段完成,然后通过ServiceLoader找到所有的VariantProcessor子类,它是task.spi模块下的一个接口,然后调用所有子类的process方法,先来看下VariantProcessor接口的定义:
1
2
3
4
5
6
7
8
9
|
package com.didiglobal.booster.task.spi
import com.android.build.gradle.api.BaseVariant
interface VariantProcessor {
fun process(variant: BaseVariant)
}
|
比如在toast模块下有如下子类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package com.didiglobal.booster.transform.toast
import com.android.build.gradle.api.BaseVariant
import com.android.build.gradle.api.LibraryVariant
import com.didiglobal.booster.gradle.isDynamicFeature
import com.didiglobal.booster.gradle.scope
import com.didiglobal.booster.gradle.variantData
import com.didiglobal.booster.task.spi.VariantProcessor
import com.google.auto.service.AutoService
@AutoService(VariantProcessor::class)
class ToastVariantProcessor : VariantProcessor {
override fun process(variant: BaseVariant) {
//如果变体不是LibraryVariant,LibraryVariant只出现在library的module中,并且变体不是一个动态模块,动态模块是Android App Bundle(.aab)结构中一的一部分,允许按需下载和安装模块,然后添加instrument-toast的aar依赖
if (variant !is LibraryVariant && !variant.variantData.isDynamicFeature()) {
variant.scope.globalScope.project.dependencies.add("implementation", "${Build.GROUP}:booster-android-instrument-toast:${Build.VERSION}")
}
}
}
|
通过AutoService注解找到ToastVariantProcessor这个子类,而上面分析boosterPlugin的时候,VariantProcessor的process方法是在配置完后调用的,也就是每一个module的build.gradle解析完事之后。ToastVariantProcessor中的process方法判断如果变体不是LibraryVariant,LibraryVariant只出现在library的module中,并且变体不是一个动态模块,动态模块是Android App Bundle(.aab)结构中一的一部分,允许按需下载和安装模块,然后添加instrument-toast的aar依赖。
来看下booster-android-instrument-toast的主要构成:
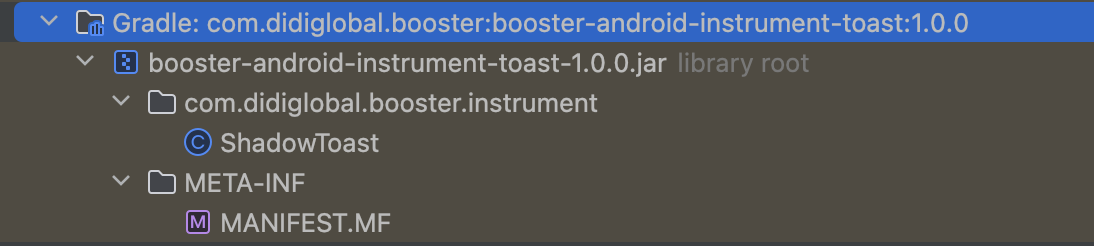 这不就是上面要将Toast的调用要替换成目标ShadowToast类吗?所以不难看出,其实对应的booster-android-instrument-toast模块就是将ShadowToast引入进来,方便asm操作字节码的时候能够替换,下面来看下如何替换的字节码。
这不就是上面要将Toast的调用要替换成目标ShadowToast类吗?所以不难看出,其实对应的booster-android-instrument-toast模块就是将ShadowToast引入进来,方便asm操作字节码的时候能够替换,下面来看下如何替换的字节码。
我们回到上面注册的BoosterAppTransform,它是核心流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
package com.didiglobal.booster.gradle
import com.android.build.api.transform.QualifiedContent
/**
* Represents android transform for application project
*
* @author johnsonlee
*/
class BoosterAppTransform : BoosterTransform() {
override fun getScopes(): MutableSet<in QualifiedContent.Scope> = SCOPE_FULL_WITH_FEATURES
}
|
它是继承自BoosterTransform,所以接着看BoosterTransform的transform方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
final override fun transform(invocation: TransformInvocation?) {
invocation?.let {
//BoosterTransformInvocation是一个代理类
BoosterTransformInvocation(it).apply {
//①
dumpInputs(this)
//②
if (isIncremental) {
//③
onPreTransform(this)
doIncrementalTransform()
} else {
buildDir.file(AndroidProject.FD_INTERMEDIATES, "transforms", "dexBuilder").let { dexBuilder ->
if (dexBuilder.exists()) {
dexBuilder.deleteRecursively()
}
}
outputProvider.deleteAll()
onPreTransform(this)
doFullTransform()
}
//④
this.onPostTransform(this)
}.executor.apply {
shutdown()
awaitTermination(1, TimeUnit.MINUTES)
}
}
}
//将扫描到的jar写到inputs.txt文件中
private fun dumpInputs(invocation: BoosterTransformInvocation) {
//invocation.context.temporaryDir:获取当前transform的临时目录,然后创建inputs.txt文件
invocation.context.temporaryDir.file("inputs.txt").touch().printWriter().use { printer ->
invocation.inputs.flatMap {
it.jarInputs
}.map {
it.file
}.forEach(printer::println)
}
}
|
在transform方法中TransformInvocation对象是Transform核心类,它是获取所有class和输出class的处理类。接着将TransformInvocation代理到了BoosterTransformInvocation中,它是一个静态代理模式。在①处,dumpInputs方法将项目中使用到的jar都打印到transform的临时目录中的inputs.txt中:
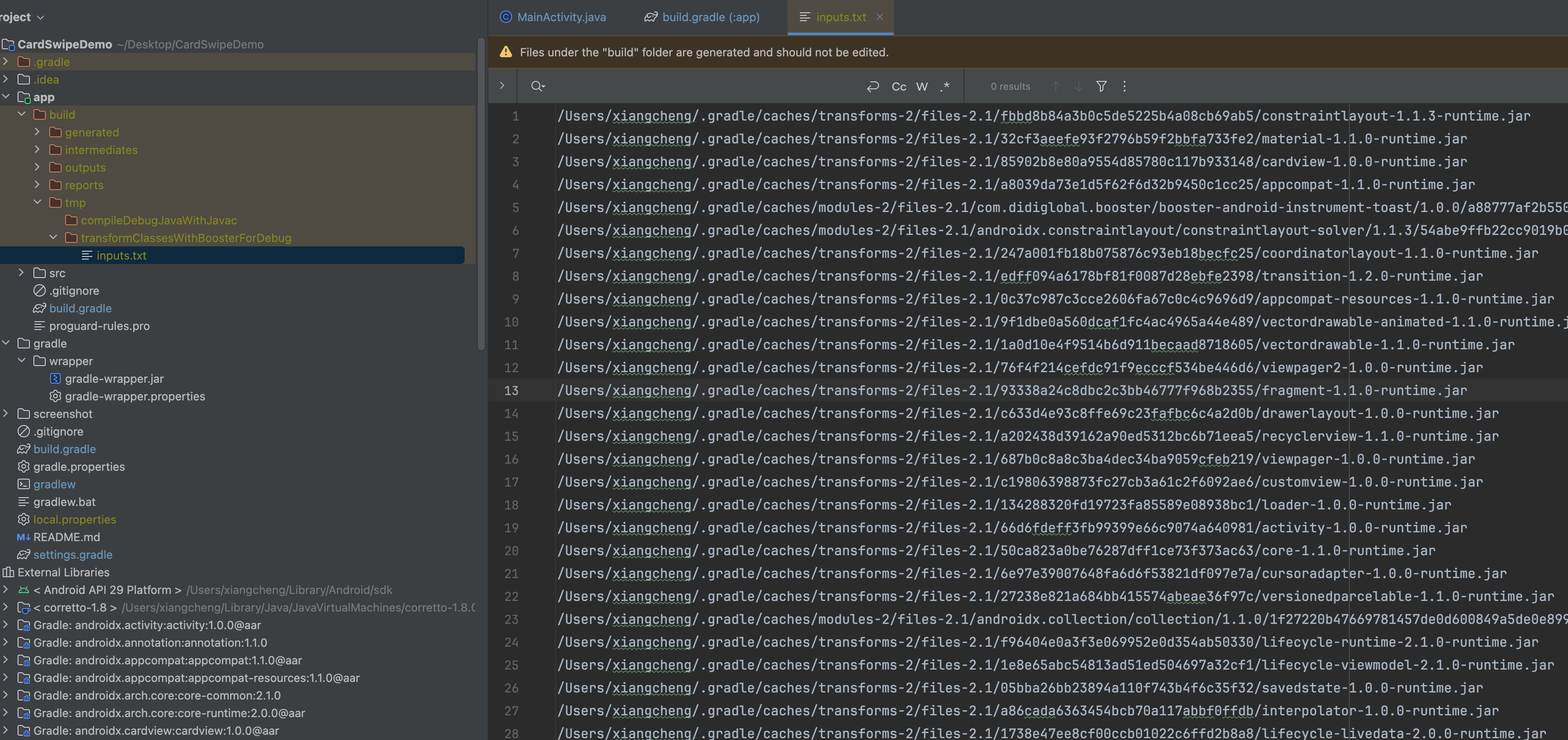 不知道这个是干嘛的,可能是为了记录所有的jar吧。在②处,判断是不是增量编译,默认是增量的,在③处,调用了BoosterTransformInvocation的onPreTransform,接着调用了doIncrementalTransform,在④处,调用了onPostTransform,这些都是BoosterTransformInvocation的方法,注意了最后是调用了executor的shutdown和awaitTermination方法。此处的executor是一个ForkJoinPool。所以重点来到BoosterTransformInvocation:
不知道这个是干嘛的,可能是为了记录所有的jar吧。在②处,判断是不是增量编译,默认是增量的,在③处,调用了BoosterTransformInvocation的onPreTransform,接着调用了doIncrementalTransform,在④处,调用了onPostTransform,这些都是BoosterTransformInvocation的方法,注意了最后是调用了executor的shutdown和awaitTermination方法。此处的executor是一个ForkJoinPool。所以重点来到BoosterTransformInvocation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
internal class BoosterTransformInvocation(private val delegate: TransformInvocation) : TransformInvocation, TransformContext, TransformListener, ArtifactManager {
/*
* Preload transformers as List to fix NoSuchElementException caused by ServiceLoader in parallel mode
*/
private val transformers = ServiceLoader.load(Transformer::class.java, javaClass.classLoader).toList()
override fun onPreTransform(context: TransformContext) = transformers.forEach {
it.onPreTransform(this)
}
@Suppress("NON_EXHAUSTIVE_WHEN")
internal fun doIncrementalTransform() {
//①
this.inputs.parallelStream().forEach { input ->
//②
input.jarInputs.parallelStream().filter { it.status != NOTCHANGED }.forEach { jarInput ->
when (jarInput.status) {
REMOVED -> jarInput.file.delete()
CHANGED, ADDED -> {
//③
val root = outputProvider.getContentLocation(jarInput.name, jarInput.contentTypes, jarInput.scopes, Format.JAR)
project.logger.info("Transforming ${jarInput.file}")
//④
jarInput.file.transform(root) { bytecode ->
//⑤
bytecode.transform(this)
}
}
}
}
input.directoryInputs.parallelStream().forEach { dirInput ->
val base = dirInput.file.toURI()
dirInput.changedFiles.ifNotEmpty {
it.forEach { file, status ->
when (status) {
REMOVED -> file.delete()
ADDED, CHANGED -> {
val root = outputProvider.getContentLocation(dirInput.name, dirInput.contentTypes, dirInput.scopes, Format.DIRECTORY)
project.logger.info("Transforming $file")
file.transform(File(root, base.relativize(file.toURI()).path)) { bytecode ->
bytecode.transform(this)
}
}
}
}
}
}
}
}
private fun ByteArray.transform(invocation: BoosterTransformInvocation): ByteArray {
return transformers.fold(this) { bytes, transformer ->
transformer.transform(invocation, bytes)
}
}
override fun onPostTransform(context: TransformContext) = transformers.forEach {
it.onPostTransform(this)
}
}
|
这里我把几个重点方法给搬过来了,BoosterTransformInvocation继承自TransformInvocation,而构造器中传入了BoosterTransform中的TransformInvocation,最终代理到了这个TransformInvocation。在onPreTransform中遍历Transformer,然后调用onPreTransform。
在doIncrementalTransform的①处中通过parallelStream遍历TransformInput集合,其中parallelStream是集合流的一种处理方式,它能并行遍历对象,一般适合大量数据的时候,在②处遍历TransformInput中的jarInputs,如果是REMOVED状态则直接删除,如果是更新、添加状态,则会走到③处,通过TransformOutputProvider获取到jar的输出路径。在④处拿到jar的file对象,然后调用扩展的transform,获取到jar中的byteArray。经过⑤处的byteArray的transform操作后,也就是字节码操作,然后在jar的transform中再写回到③中的root中。下面看下File的transform扩展方法是如何获取到byteArray,并回写到root中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
/**
* Transform this file or directory to the output by the specified transformer
*
* @param output The output location
* @param transformer The byte data transformer
*/
fun File.transform(output: File, transformer: (ByteArray) -> ByteArray = { it -> it }) {
when {
isDirectory -> {
val base = this.toURI()
this.search().forEach {
it.transform(File(output, base.relativize(it.toURI()).path), transformer)
}
}
isFile -> {
when (output.extension.toLowerCase()) {
//如果当前file是一个jar,①
"jar" -> JarFile(this).use {
//②
it.transform(output, ::JarArchiveEntry, transformer)
}
//如果当前file是一个class,③
"class" -> inputStream().use {
logger.info("Transforming ${this.absolutePath}")
//④
it.transform(transformer).redirect(output)
}
else -> this.copyTo(output, true)
}
}
else -> TODO("Unexpected file: ${this.absolutePath}")
}
}
|
整个transform方法,有两个参数一个是目标路径,第二个参数就是字节码操作的闭包。闭包返回的是ByteArray,也就是修改前的字节码数据。
在①处,如果当前File是一个jar的时候,会初始化一个JarFile,然后调用use扩展函数,其中use方法是对Closeable类型做的异常处理,流的关闭处理。在②处调用JarFile的transform扩展函数,其中JarFile是ZipFile的子类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
fun ZipFile.transform(output: File, entryFactory: (ZipEntry) -> ZipArchiveEntry = ::ZipArchiveEntry, transformer: (ByteArray) -> ByteArray = { it -> it }) {
//①
val creator = ParallelScatterZipCreator(Executors.newWorkStealingPool())
val entries = mutableSetOf<String>()
//②
entries().asSequence().forEach { entry ->
//③
if (!entries.contains(entry.name)) {
//④
val zae = entryFactory(entry)
//⑤
val stream = InputStreamSupplier {
when (entry.name.substringAfterLast('.', "")) {
//⑥
"class" -> getInputStream(entry).use { src ->
logger.info("Transforming ${this.name}!/${entry.name}")
src.transform(transformer).inputStream()
}
//⑦
else -> getInputStream(entry)
}
}
//⑧
creator.addArchiveEntry(zae, stream)
entries.add(entry.name)
} else {
logger.error("Duplicated jar entry: ${this.name}!/${entry.name}")
}
}
//⑨
ZipArchiveOutputStream(output.touch()).use { it ->
creator.writeTo(it)
}
}
|
在①处创建ParallelScatterZipCreator,它是多线程并行压缩多个文件,然后再合并到一个总的压缩文件中,常见的ZipOutputStream是单线程进行压缩所有的文件。在②处拿到ZipFile的entries数组,然后调用asSequence进行遍历,entries方法是一个ZipEntryIterator对象,其实它也有toList方法,在此处都是遍历,其实和list没有区别,Sequence区别是在处理中间操作符的时候不会创建临时的集合对象,比如map,filter等。在③主要是去重,在④处将ZipEntry转化成ZipArchiveEntry,方便给到ParallelScatterZipCreator。在⑤处构建InputStreamSupplier,它是一个接口,在get方法中返回InputStream,方便使用闭包。在⑥处通过ZipEntry获取到对应的inputStream,然后调用src(inputStream)的transform扩展方法,并把transformer闭包传入其中:
1
2
3
|
fun InputStream.transform(transformer: (ByteArray) -> ByteArray): ByteArray {
return transformer(readBytes())
}
|
可以看到通过InputStream的readBytes扩展方法获取到ByteArray:
1
2
3
4
5
|
private fun InputStream.readBytes(estimatedSize: Int = DEFAULT_BUFFER_SIZE): ByteArray {
val buffer = ByteArrayOutputStream(Math.max(estimatedSize, this.available()))
copyTo(buffer)
return buffer.toByteArray()
}
|
其中最终通过构造ByteArrayOutputStream对象,然后调用InputStream的copyTo扩展方法将buffer复制到ByteArrayOutputStream中L
1
2
3
4
5
6
7
8
9
10
11
|
private fun InputStream.copyTo(out: OutputStream, bufferSize: Int = DEFAULT_BUFFER_SIZE): Long {
var bytesCopied: Long = 0
val buffer = ByteArray(bufferSize)
var bytes = read(buffer)
while (bytes >= 0) {
out.write(buffer, 0, bytes)
bytesCopied += bytes
bytes = read(buffer)
}
return bytesCopied
}
|
获取到file的byteArray后,交给了transformer进行修改字节码,剩下就是写回到目标路径中,回到上面ZipFile的transform⑥处,最终将ByteArray通过inputStream扩展方法转化成
ByteArrayInputStream:
1
2
|
@kotlin.internal.InlineOnly
public inline fun ByteArray.inputStream(): ByteArrayInputStream = ByteArrayInputStream(this)
|
所以最终的ByteArrayInputStream给到了⑤处InputStreamSupplier的get方法返回值了。在⑦中,如果不是class类型的entry,则不进行transform的闭包修改。在⑧处将修改后的InputStream添加到ParallelScatterZipCreator中,并添加到entries集合中,方便去重。在⑨处,通过ZipArchiveOutputStream的输出流回写到output目标文件中。整个修改并回写过程分为这9大步骤。关于file是目录结构和非目录结构中的class文件处理就不说了,代码很简单。
BoosterTransformInvocation中全量编译过程就不分析了,和增量编译大差不差。
小结:
booster中修改字节码过程是在BoosterTransformInvocation中,它将具体的修改交给了Transformer的子类,其中修改步骤是先遍历TransformInput中JarInput和directoryInput的class文件,然后获取到class的byteArray,然后经过Transformer子类的transform方法修改byteArray,修改完后,再回写到原始class对应的目录中,这样就达到了修改并覆盖class的目的。
前面分析了boosterPlugin中会遍历Transform的子类然后执行它的transform方法,其中AsmTransformer是实现了Transformer接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
@AutoService(Transformer::class)
class AsmTransformer : Transformer {
/*
* Preload transformers as List to fix NoSuchElementException caused by ServiceLoader in parallel mode
*/
private val transformers = ServiceLoader.load(ClassTransformer::class.java, javaClass.classLoader).toList()
override fun transform(context: TransformContext, bytecode: ByteArray): ByteArray {
return ClassWriter(ClassWriter.COMPUTE_MAXS).also { writer ->
transformers.fold(ClassNode().also { klass ->
ClassReader(bytecode).accept(klass, 0)
}) { klass, transformer ->
transformer.transform(context, klass)
}.accept(writer)
}.toByteArray()
}
override fun onPreTransform(context: TransformContext) {
transformers.forEach {
it.onPreTransform(context)
}
}
override fun onPostTransform(context: TransformContext) {
transformers.forEach {
it.onPostTransform(context)
}
}
}
|
AsmTransformer通过AutoService注解被扫描到是Transformer的子类,我们将它的transform写成如下方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
override fun transform(context: TransformContext, bytecode: ByteArray): ByteArray {
// ClassNode是ASM tree API的类
var classNode = ClassNode()
val classReader = ClassReader(bytecode)
// accept()方法,读取bytecode的相关.class信息赋值到classNode对象的相应字段
classReader.accept(classNode,0)
transformers.foreach { transformer ->
// 每次transform后,class的内容变化都缓存在classNodes中
// 注意此时的classNode对象的内容就是bytecode的内容,只是格式不同而已
transformer.transform(context, classNode)
}
//ClassWriter是ASM core API的类 ,专门用来写出修改后class的类
val classWriter = ClassWriter(ClassWriter.COMPUTE_MAXS)
//将写好后的classNode回写到classWriter中
classNode.accept(classWriter)
// classWriter把被洗礼后的classNode,即ClassNode对象,
// 写成ByteArray返回到上层BoosterTransformInvocation
return classWriter.toByteArray()
}
|
小结:
可以发现asm字节码操作,基本都是模版代码,首先通过classReader读取到byteArray(在前面学习asm的时候,是通过FileInputStream来读取的),然后把class信息映射到classNode对象上。然后遍历字节码操作类,将要修改的classNode给到操作类,修改完后,将classNode同步到classWriter上,最后把修改后的byteArray回写到上层中。
上面分析过会通过ClassTransformer的子类来修改字节码,toast字节码的修改是在ToastTransformer这个子类中,主要来看下它的transform方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
private const val TOAST = "android/widget/Toast"
private const val SHADOW_TOAST = "com/didiglobal/booster/instrument/ShadowToast"
override fun transform(context: TransformContext, klass: ClassNode): ClassNode {
//①
if (klass.name == SHADOW_TOAST) {
return klass
}
klass.methods.forEach { method ->
//②
method.instructions?.iterator()?.asIterable()?.filterIsInstance(MethodInsnNode::class.java)?.filter {
//③
it.opcode == Opcodes.INVOKEVIRTUAL && it.name == "show" && it.desc == "()V" && (it.owner == TOAST || context.klassPool.get(TOAST).isAssignableFrom(it.owner))
}?.forEach {
//④
it.optimize(klass, method)
}
}
return klass
}
//⑤
private fun MethodInsnNode.optimize(klass: ClassNode, method: MethodNode) {
logger.println(" * ${this.owner}.${this.name}${this.desc} => $SHADOW_TOAST.apply(L$SHADOW_TOAST;)V: ${klass.name}.${method.name}${method.desc}")
this.owner = SHADOW_TOAST
this.name = "show"
this.desc = "(L$TOAST;)V"
this.opcode = Opcodes.INVOKESTATIC
this.itf = false
}
|
上面transform方法中,在①处如果当前class是com/didiglobal/booster/instrument/ShadowToast,则不处理,在②处通过method.instructions拿到当前方法的所有的指令集,然后通过filterIsInstance过滤是方法调用指令,比如INVOKEVIRTUAL、INVOKESTATIC、INVOKESPECIAL 和 INVOKEINTERFACE,因为MethodInsnNode代表的是方法调用指令。所以在③处通过opcode、name、desc、owner来判断是不是要修改的字节码,我们可以通过工具来看下:
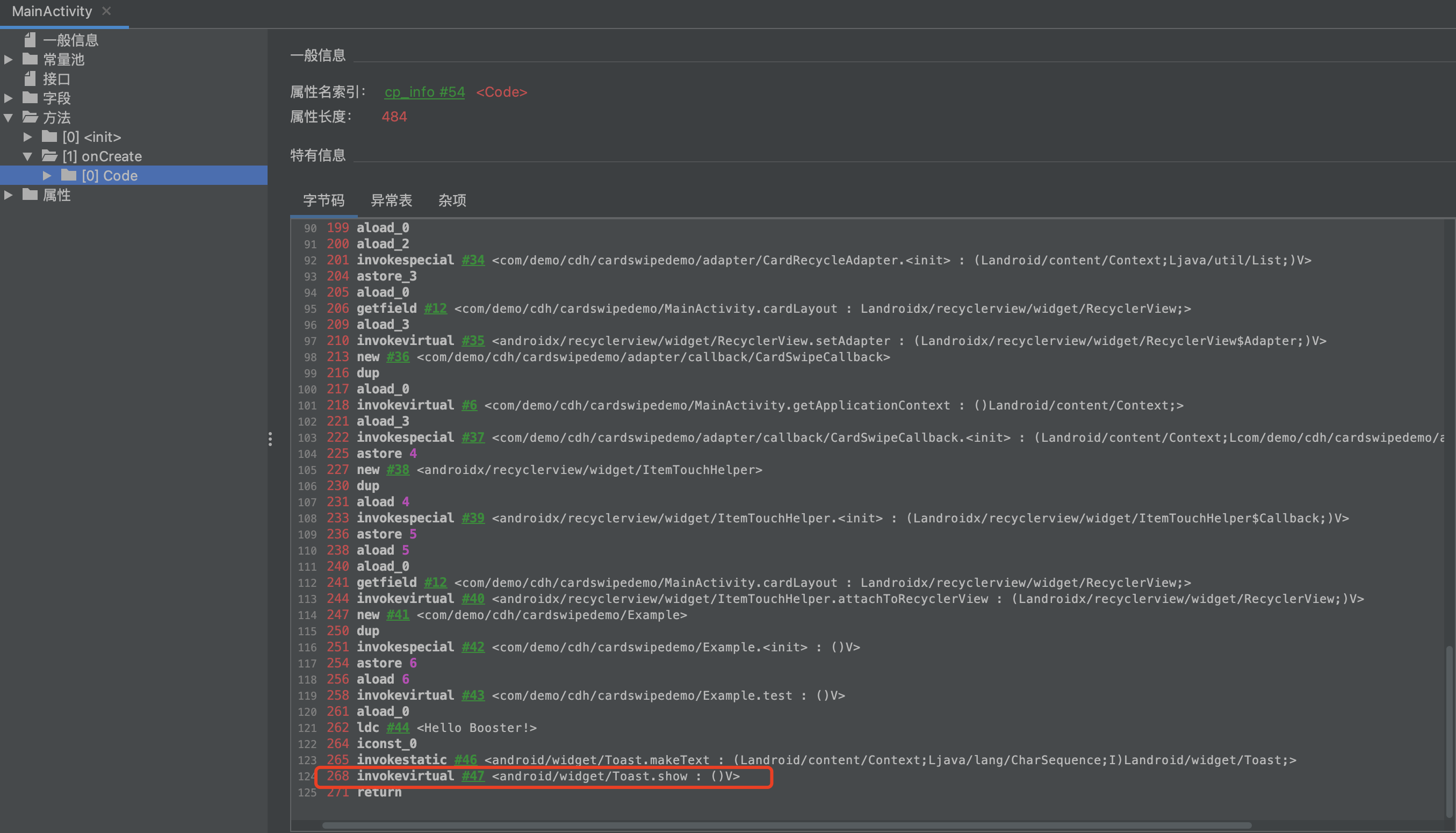 可以看到,修改前的字节码的
可以看到,修改前的字节码的opcode=invokevirtual,name=show,desc = ()V,owner = android/widget/Toast,所以通过上面的过滤条件,就能过滤出要修改的指令。在④处,调用了MethodInsnNode的扩展方法optimize,在⑤处就是修改字节码了,如果不知道修改后的字节码,我们可以借助工具查看:
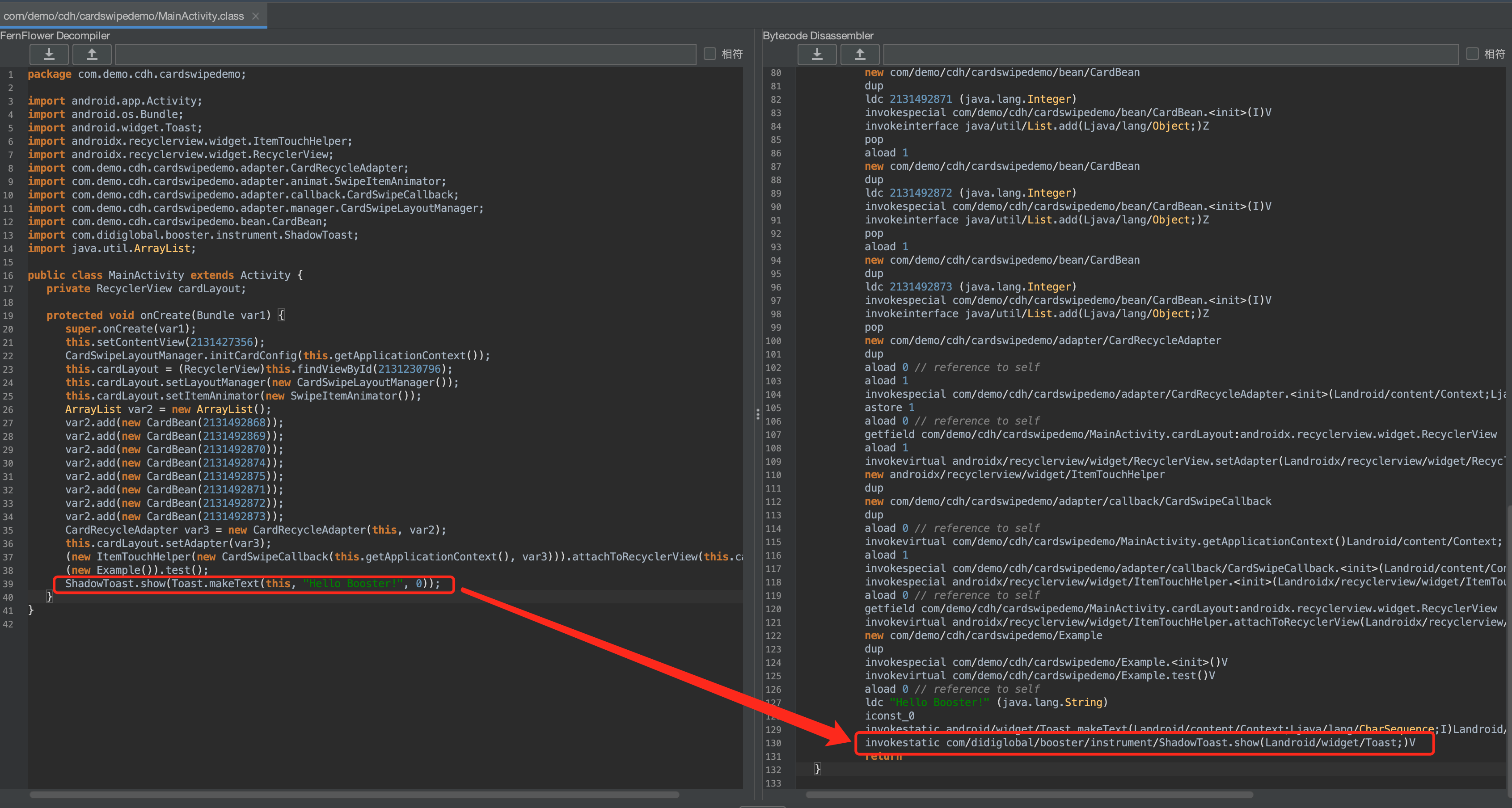 可以看到最终的opcode= invokestatic,name = show,desc = (Landroid/widget/Toast;)V,owner = com/didiglobal/booster/instrument/ShadowToast。和上面optimize方法中修改的指令一样,新加了itf = false,表示新替换的owner是否是接口,此处的ShadowToast不是一个接口,所以为false,这就是替换指令的过程,是不是很简单。
可以看到最终的opcode= invokestatic,name = show,desc = (Landroid/widget/Toast;)V,owner = com/didiglobal/booster/instrument/ShadowToast。和上面optimize方法中修改的指令一样,新加了itf = false,表示新替换的owner是否是接口,此处的ShadowToast不是一个接口,所以为false,这就是替换指令的过程,是不是很简单。
下面来实操一波,将某个类中的方法调用改成其它的方法调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package com.xc.asm;
public class Main {
public static void main(String[] args) {
System.out.println("Hello world!");
}
public static void test(){
System.out.println("Main中的test方法");
}
public static void test1(){
System.out.println("Main中的test1方法");
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
package com.xc.asm;
public class C {
public void m() throws Exception {
Thread.sleep(100);
}
public void n(){
Main.test();
}
}
|
在C类中调用了Main类中的test静态方法,我们这里是想把调用test方法给替换成test1方法,话不多说,直接撸🐴:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public class MethodReplaceTest {
public static void main(String[] args) throws Exception {
Class clazz = C.class;
String clazzFilePath = Utils.getClassFilePath(clazz);
ClassReader classReader = new ClassReader(new FileInputStream(clazzFilePath));
//ClassWriter.COMPUTE_FRAMES表示自动计算方法栈数
ClassWriter classWriter = new ClassWriter(ClassWriter.COMPUTE_FRAMES);
//通过构造一个新的classVisitor,然后将classWriter传入到该classVistor中,实际干活的还是classWriter,MethodReplaceClassVisitor只是作为一个代理类,进行添加属性
MethodReplaceClassVisitor methodReplaceClassVisitor = new MethodReplaceClassVisitor(Opcodes.ASM5, classWriter);
classReader.accept(methodReplaceClassVisitor, 0);
// 写入文件
byte[] bytes = classWriter.toByteArray();
FileOutputStream fos = new FileOutputStream(clazzFilePath);
fos.write(bytes);
fos.flush();
fos.close();
//验证结果
C c = new C();
c.n();
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public class MethodReplaceClassVisitor extends ClassVisitor {
protected MethodReplaceClassVisitor(int api, ClassVisitor classVisitor) {
super(api, classVisitor);
}
@Override
public MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) {
MethodVisitor methodVisitor = super.visitMethod(access, name, descriptor, signature, exceptions);
if(name.equals("n")){
return new MethodReplaceMethodVisitor(Opcodes.ASM5,methodVisitor);
}
return methodVisitor;
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public class MethodReplaceMethodVisitor extends MethodVisitor {
protected MethodReplaceMethodVisitor(int api, MethodVisitor methodVisitor) {
super(api, methodVisitor);
}
@Override
public void visitMethodInsn(int opcode, String owner, String name, String descriptor, boolean isInterface) {
if (mv != null) {
mv.visitMethodInsn(Opcodes.INVOKESTATIC,"com/xc/asm/Main","test1","()V",false);
}
}
}
|
关于asm的基础操作就不多说了,主要看下MethodReplaceMethodVisitor的visitMethodInsn方法是操作方法指令的,通过传进来的MethodVisitor,来进行修改指令,其中指令中的name字段传test1,其余的字段和原来调用test方法一致的。
参考:
滴滴开源库Booster:架构运作及源码分析